在移动 AI 领域的重大举措中,苹果的研究人员开源了 MobileCLIP 及其强大的后续版本 MobileCLIP 2。这些图像文本模型旨在以卓越的效率提供桌面级性能,为新一代智能、响应迅速且私密的设备端应用铺平道路。
该项目在 CVPR 2024 和著名的 TMLR 期刊的论文中详细介绍,专注于解决 AI 中的关键挑战:使强大的模型足够小且快速,能够直接在移动设备上运行而不牺牲准确性。完整的代码套件、预训练模型和数据集现已在 GitHub 和 Hugging Face 上向公众开放。
性能一览
结果不言自明。MobileCLIP 模型始终优于或匹配更大、计算成本更高的模型,同时在 iPhone 12 Pro Max 等移动硬件上运行速度显著更快。
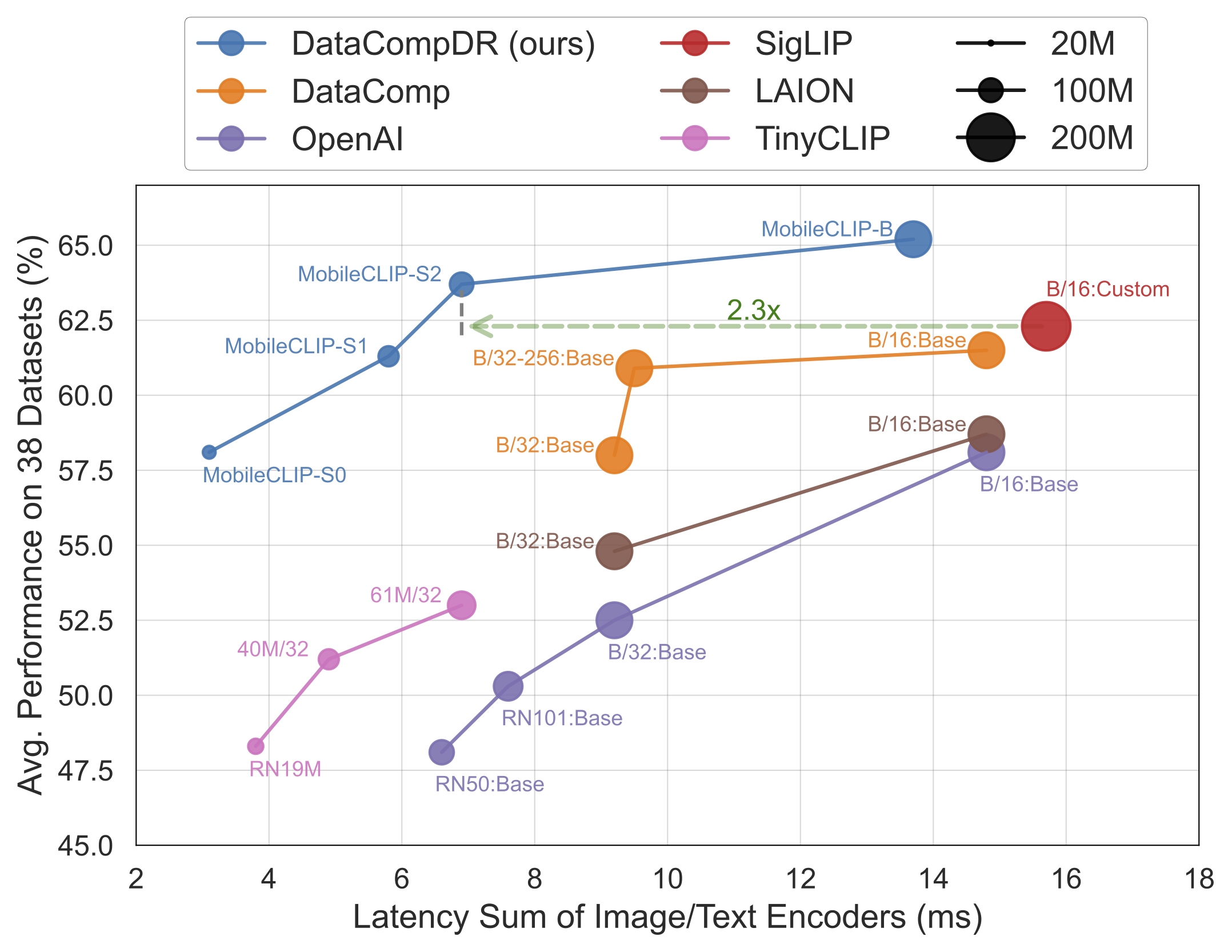
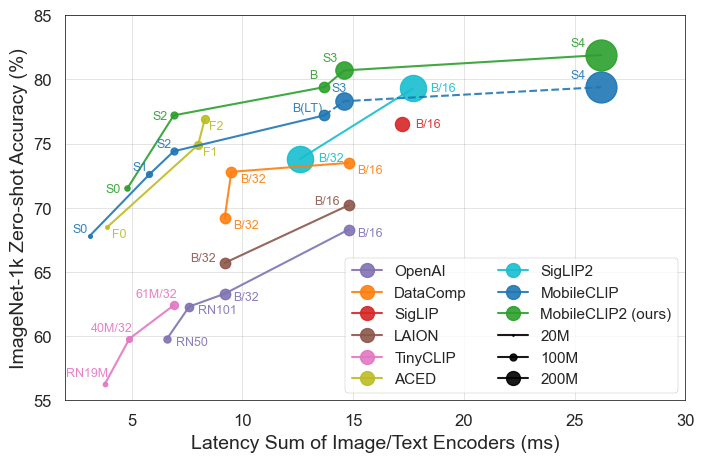
发布的主要亮点
- 峰值效率:最小的模型
MobileCLIP-S0达到与 OpenAI 广泛使用的 ViT-B/16 模型相似的性能,但速度快 4.8 倍,体积小 2.8 倍。 - 最先进的速度:
MobileCLIP2-S4以一半的参数匹配强大的 SigLIP-SO400M/14 模型的准确性,并以 2.5 倍更低的延迟超越 DFN ViT-L/14。 - 突破性训练:模型使用新颖的"多模态强化训练"技术在新开发的数据集(DataCompDR 和 DFNDR)上进行训练,这是其增强效率的关键因素。
- 开发者友好:模型现在在流行的 OpenCLIP 库中得到原生支持,使其易于集成到现有项目中。
技术深度解析
MobileCLIP 的出色性能源于几个关键创新:
- 多模态强化训练:一种新颖的训练策略,增强模型有效连接图像和文本的能力,以更少的资源实现更高的准确性。
- 专门策划的数据集:模型在
DataCompDR和DFNDR上进行训练,这些是专门为提高图像文本模型的鲁棒性和效率而大规模生成的海量数据集。 - 高效的移动架构:模型中的视觉塔基于 MobileOne 等高效架构,针对移动 CPU 和 GPU 的高性能进行了优化。
为什么这对开发者和消费者很重要
通过开源这些工具,苹果正在赋能开发者构建以前只有强大云服务器才能实现的复杂 AI 功能。这意味着应用程序可以直接在用户设备上执行复杂任务,如实时物体识别、视觉搜索和高级图像字幕。
对消费者的好处是双重的:隐私和速度。设备端处理意味着个人照片等敏感数据永远不必离开手机。此外,操作是即时的,没有向服务器发送数据和从服务器接收数据的延迟。该项目甚至包括一个 iOS 演示应用程序来展示这些实时分类功能。
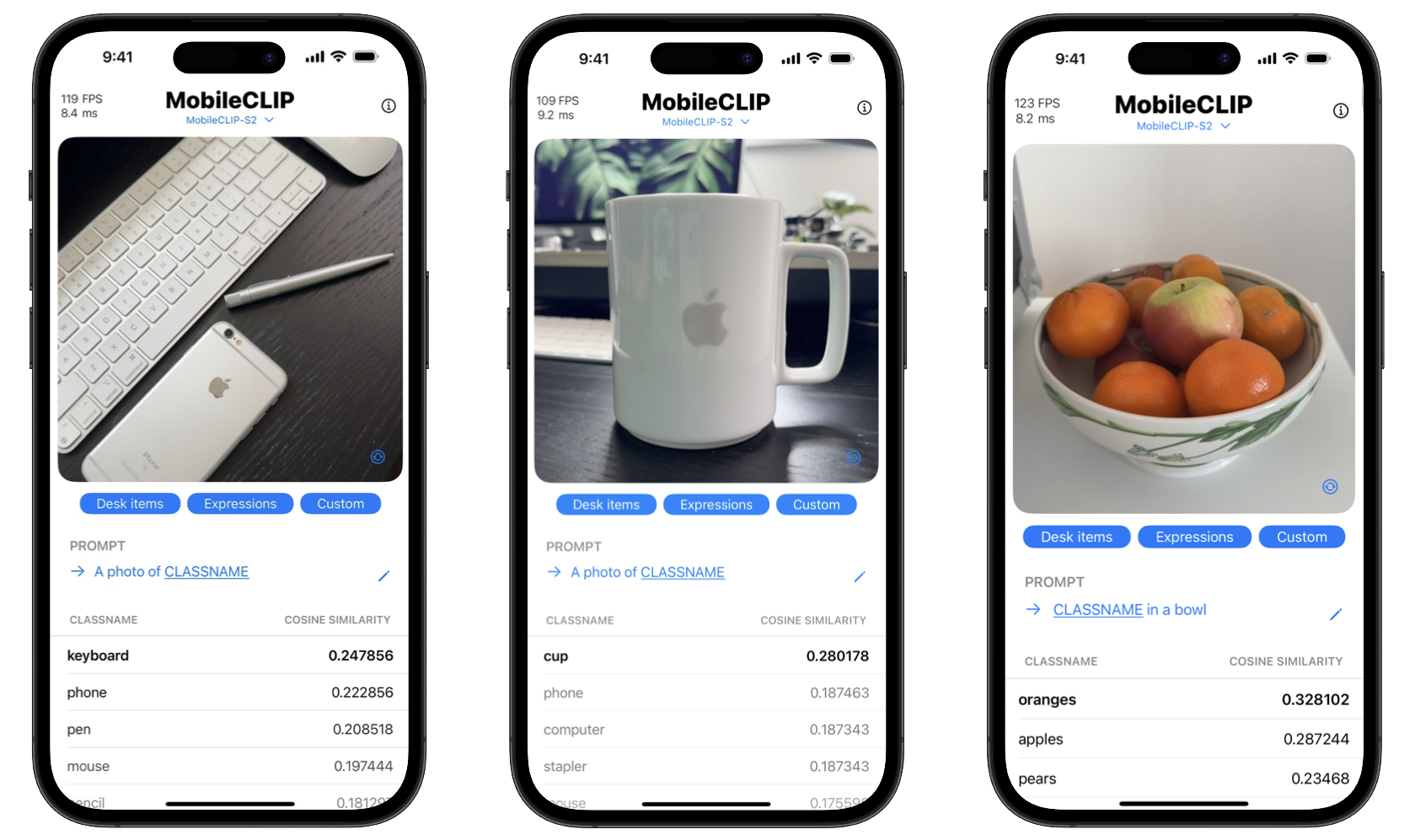
开始使用 MobileCLIP
开发者可以立即开始试验 MobileCLIP。模型在 Hugging Face 上可用,完整的源代码、训练脚本和评估工具可以在官方 GitHub 存储库中找到。
快速安装
conda create -n clipenv python=3.10
conda activate clipenv
pip install -e .