モバイルAI分野における重要な動きとして、Appleの研究者がMobileCLIPとその強力な後継版MobileCLIP 2をオープンソース化しました。これらの画像テキストモデルは、卓越した効率性でデスクトップクラスの性能を提供するよう設計されており、新世代のインテリジェントで応答性が高く、プライベートなオンデバイスアプリケーションへの道を開いています。
CVPR 2024と権威あるTMLRジャーナルの論文で詳述されたこのプロジェクトは、AIにおける重要な課題の解決に焦点を当てています:精度を犠牲にすることなく、モバイルデバイス上で直接実行できるほど小さく高速な強力なモデルを作ることです。コード、事前訓練済みモデル、データセットの完全なスイートが、GitHubとHugging Faceで一般公開されています。
パフォーマンス概要
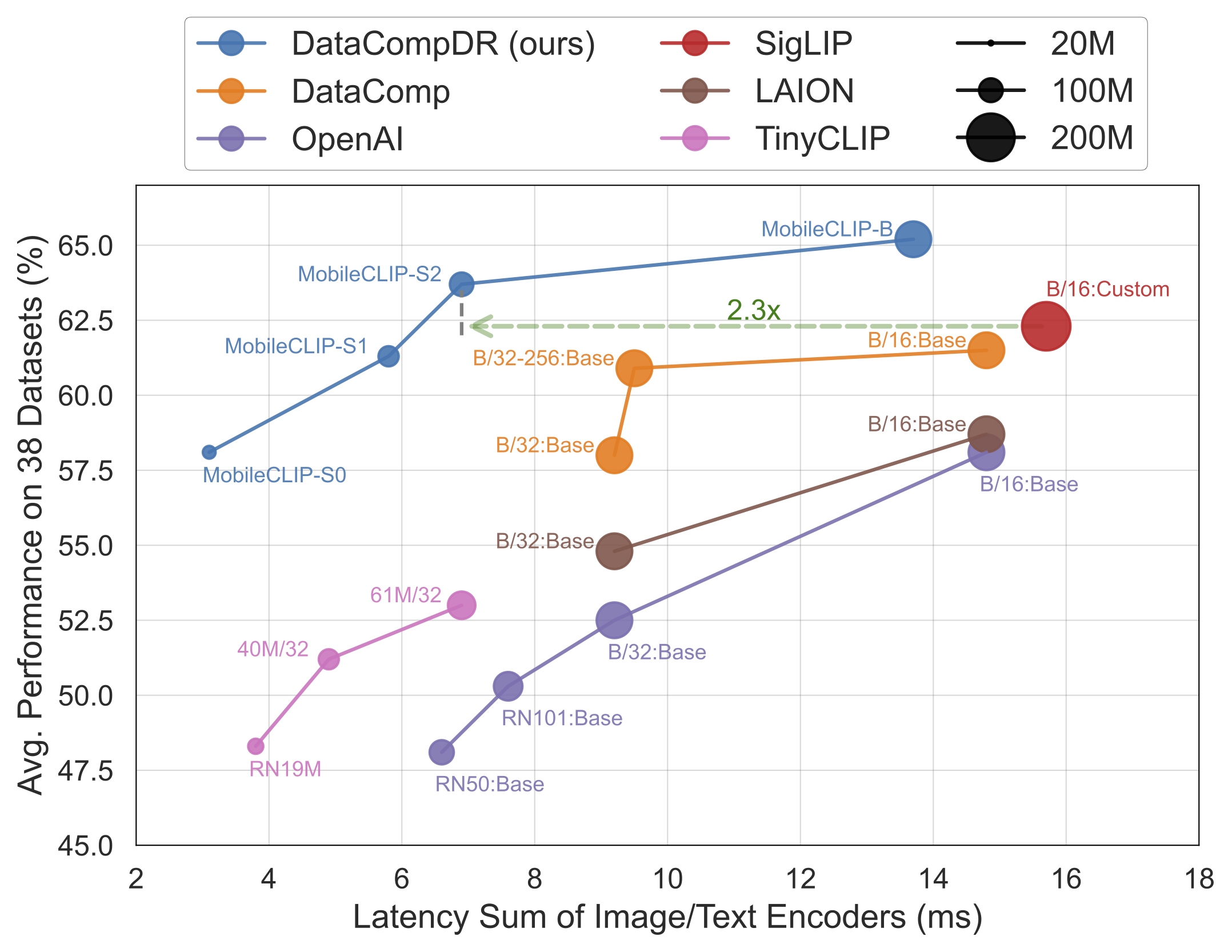
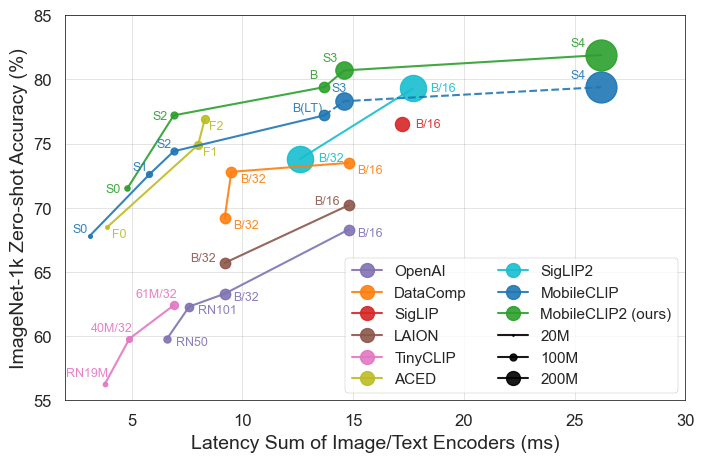
結果は明らかです。MobileCLIPモデルは、iPhone 12 Pro Maxなどのモバイルハードウェア上で大幅に高速に動作しながら、より大きく計算コストの高いモデルを一貫して上回るか、同等の性能を発揮します。
リリースの主要ハイライト
- ピーク効率:最小モデル
MobileCLIP-S0は、OpenAIの広く使用されているViT-B/16モデルと同様の性能を達成しながら、4.8倍高速で2.8倍小さいです。 - 最先端の速度:
MobileCLIP2-S4は、パラメータ数が半分で強力なSigLIP-SO400M/14モデルの精度に匹敵し、DFN ViT-L/14を2.5倍低いレイテンシーで上回ります。 - 画期的な訓練:モデルは新開発されたデータセット(DataCompDRとDFNDR)で新しい「マルチモーダル強化訓練」技術を使用して訓練されており、これが効率向上の重要な要因です。
- 開発者フレンドリー:モデルは人気のOpenCLIPライブラリでネイティブサポートされ、既存プロジェクトへの統合が容易です。
技術的詳細
MobileCLIPの印象的な性能は、いくつかの重要な革新から生まれています:
- マルチモーダル強化訓練:画像とテキストを効果的に接続するモデルの能力を向上させる新しい訓練戦略で、より少ないリソースでより高い精度を実現します。
- 特別に厳選されたデータセット:モデルは
DataCompDRとDFNDRで訓練されました。これらは画像テキストモデルの堅牢性と効率性を向上させるために大規模に生成された巨大なデータセットです。 - 効率的なモバイルアーキテクチャ:モデルのビジョンタワーは、モバイルCPUとGPUでの高性能に最適化されたMobileOneなどの効率的なアーキテクチャに基づいています。
開発者と消費者にとっての意義
これらのツールをオープンソース化することで、Appleは開発者が以前は強力なクラウドサーバーでのみ可能だった高度なAI機能を構築できるよう支援しています。これにより、アプリはリアルタイム物体認識、視覚検索、高度な画像キャプションなどの複雑なタスクをユーザーのデバイス上で直接実行できます。
消費者にとっての利点は二重です:プライバシーと速度。オンデバイス処理により、個人写真などの機密データが電話を離れる必要がありません。さらに、サーバーとのデータ送受信の遅延なしに、アクションは瞬時に実行されます。プロジェクトには、これらのリアルタイム分類機能を紹介するiOSデモアプリも含まれています。
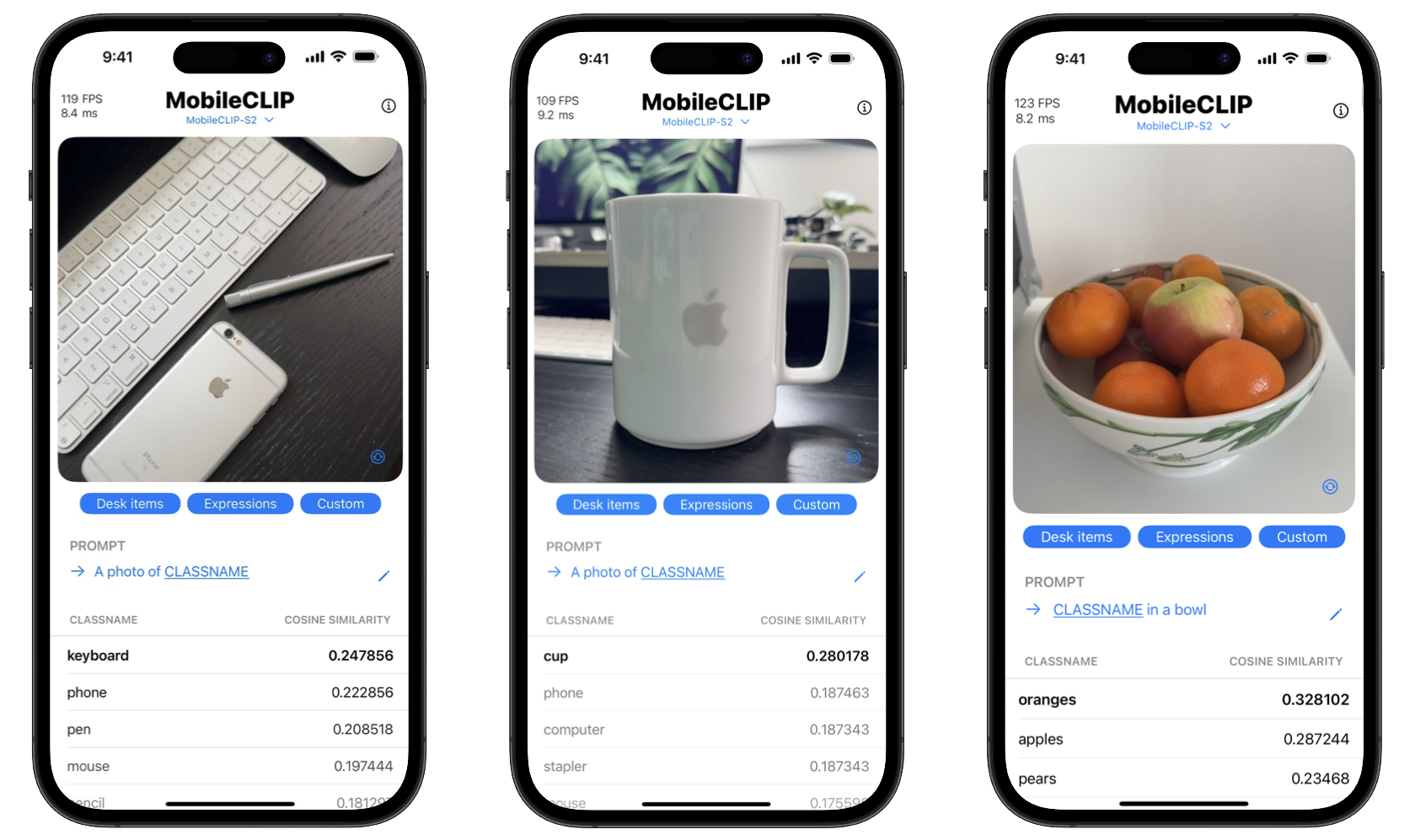
MobileCLIPを始める
開発者はすぐにMobileCLIPの実験を開始できます。モデルはHugging Faceで利用可能で、完全なソースコード、訓練スクリプト、評価ツールは公式GitHubリポジトリで見つけることができます。
クイックインストール
conda create -n clipenv python=3.10
conda activate clipenv
pip install -e .