In a significant move for the mobile AI landscape, researchers at Apple have open-sourced MobileCLIP and its powerful successor, MobileCLIP 2. These image-text models are engineered to deliver desktop-class performance with remarkable efficiency, paving the way for a new generation of intelligent, responsive, and private on-device applications.
The project, detailed in papers for CVPR 2024 and the prestigious TMLR journal, focuses on solving a critical challenge in AI: making powerful models small and fast enough to run directly on mobile devices without sacrificing accuracy. The full suite of code, pre-trained models, and datasets are now available to the public on GitHub and Hugging Face.
Performance at a Glance
The results speak for themselves. MobileCLIP models consistently outperform or match larger, more computationally expensive models while running significantly faster on mobile hardware like the iPhone 12 Pro Max.
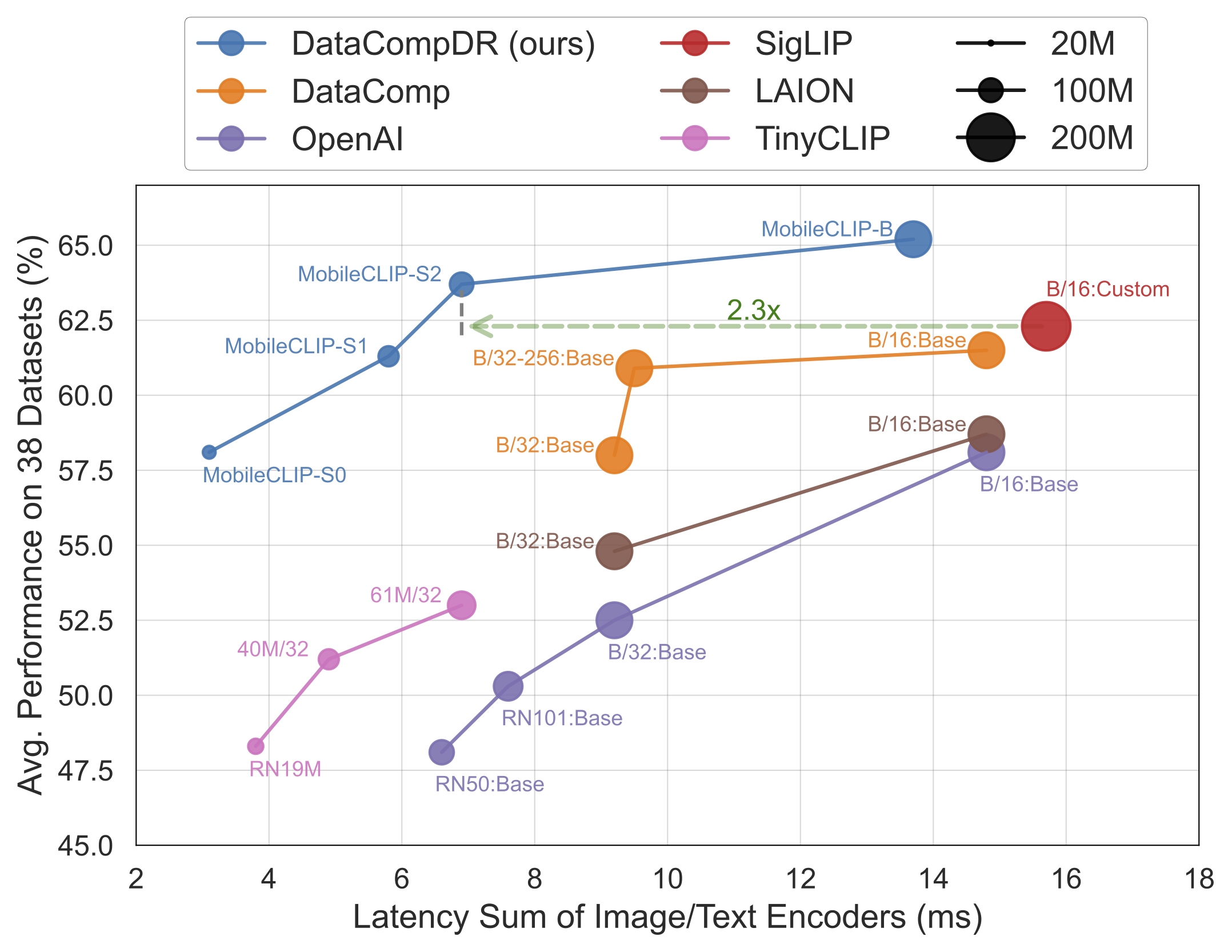
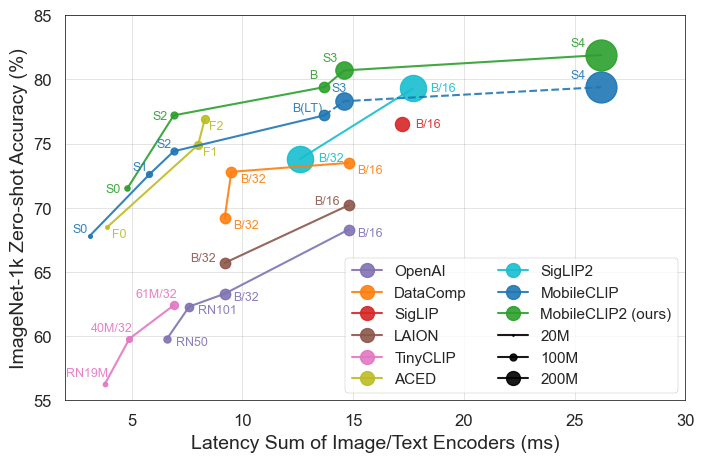
Key Highlights of the Release
- Peak Efficiency: The smallest model,
MobileCLIP-S0, achieves similar performance to OpenAI's widely-used ViT-B/16 model but is 4.8x faster and 2.8x smaller. - State-of-the-Art Speed:
MobileCLIP2-S4matches the accuracy of the powerful SigLIP-SO400M/14 model with half the parameters and surpasses DFN ViT-L/14 with 2.5x lower latency. - Breakthrough Training: The models are trained using a novel "Multi-Modal Reinforced Training" technique on newly developed datasets (DataCompDR and DFNDR), a key factor in their enhanced efficiency.
- Developer-Friendly: The models are now natively supported in the popular OpenCLIP library, making them easy to integrate into existing projects.
Technical Deep Dive
The impressive performance of MobileCLIP stems from several key innovations:
- Multi-Modal Reinforced Training: A novel training strategy that enhances the model's ability to connect images and text effectively, leading to higher accuracy with fewer resources.
- Specially Curated Datasets: The models were trained on
DataCompDRandDFNDR, massive datasets generated at scale specifically to improve the robustness and efficiency of image-text models. - Efficient Mobile Architectures: The vision towers in the models are based on efficient architectures like MobileOne, which are optimized for high performance on mobile CPUs and GPUs.
Why This Matters for Developers and Consumers
By open-sourcing these tools, Apple is empowering developers to build sophisticated AI features that were previously only possible with powerful cloud servers. This means apps can perform complex tasks like real-time object recognition, visual search, and advanced image captioning directly on a user's device.
The benefits for consumers are twofold: privacy and speed. On-device processing means sensitive data like personal photos never have to leave the phone. Furthermore, actions are instantaneous, without the lag of sending data to and from a server. The project even includes an iOS demo app to showcase these real-time classification capabilities.
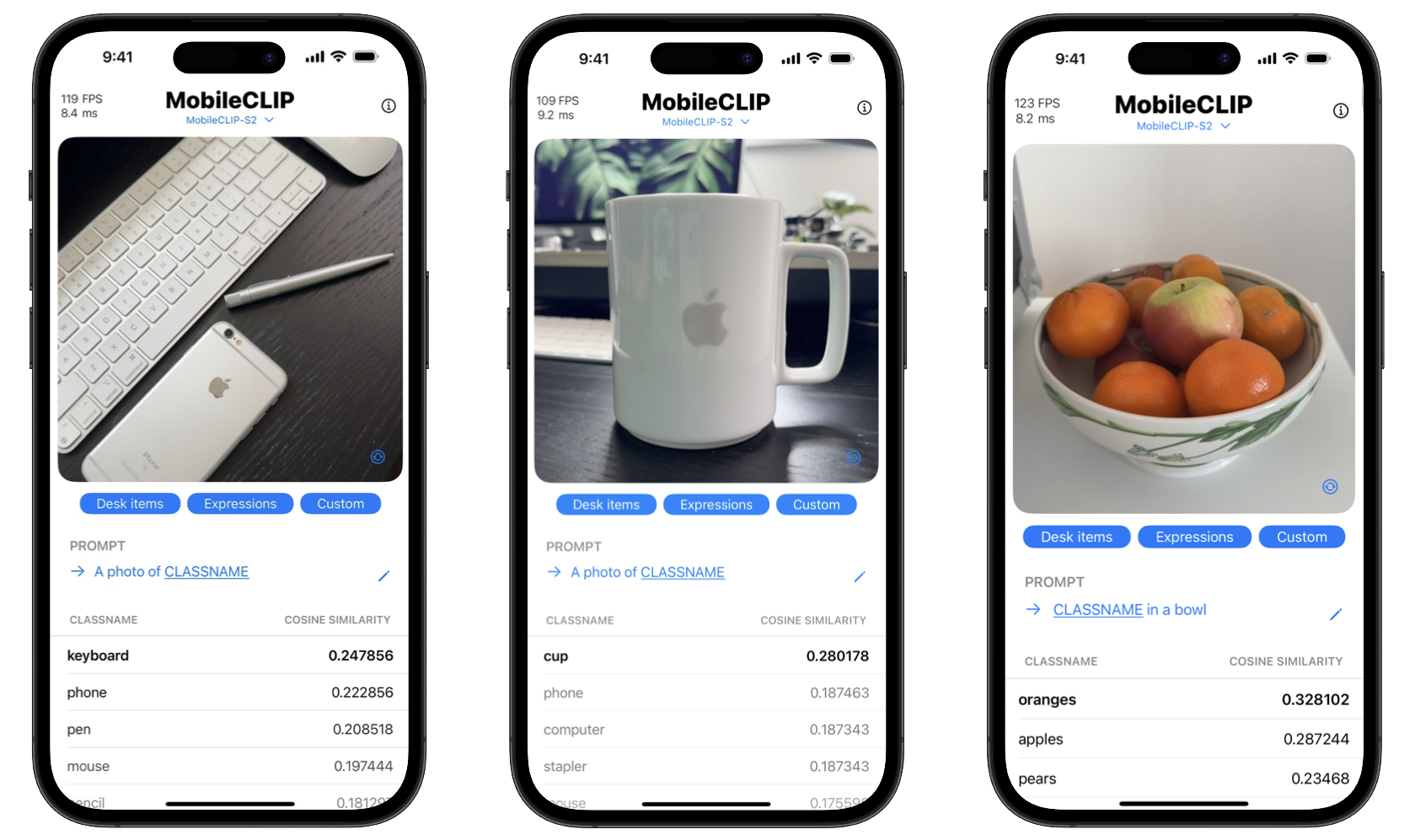
Get Started with MobileCLIP
Developers can start experimenting with MobileCLIP immediately. The models are available on Hugging Face, and the complete source code, training scripts, and evaluation tools can be found in the official GitHub repository.
Quick Installation
conda create -n clipenv python=3.10
conda activate clipenv
pip install -e .