Em um movimento significativo para o cenário de IA móvel, pesquisadores da Apple abriram o código do MobileCLIP e seu poderoso sucessor, MobileCLIP 2. Esses modelos de imagem-texto são projetados para oferecer desempenho de classe de desktop com eficiência notável, abrindo caminho para uma nova geração de aplicativos inteligentes, responsivos e privados no dispositivo.
O projeto, detalhado em artigos para a CVPR 2024 e a prestigiosa revista TMLR, foca em resolver um desafio crítico em IA: tornar modelos poderosos pequenos e rápidos o suficiente para rodar diretamente em dispositivos móveis sem sacrificar a precisão. O conjunto completo de código, modelos pré-treinados e conjuntos de dados estão agora disponíveis ao público no GitHub e no Hugging Face.
Desempenho em Resumo
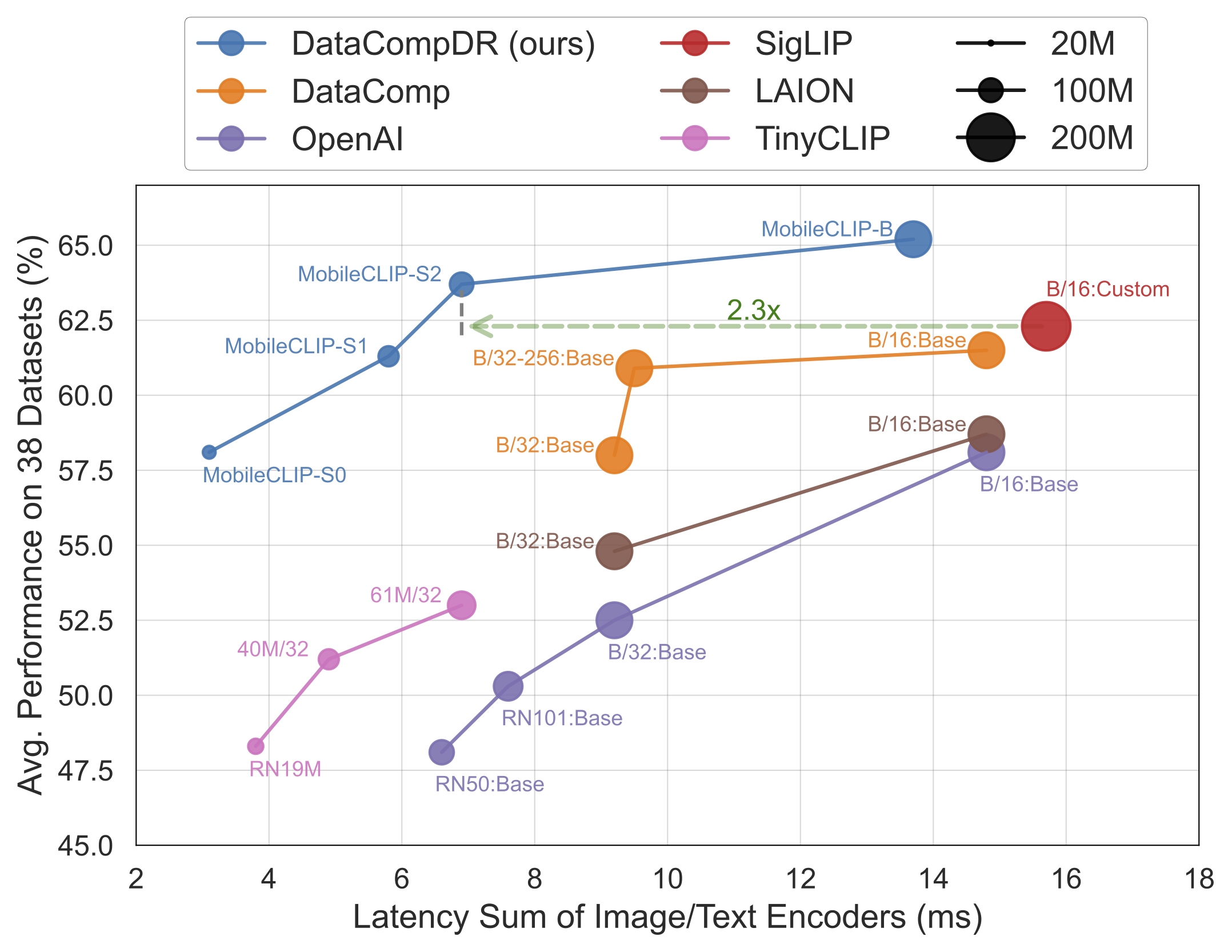
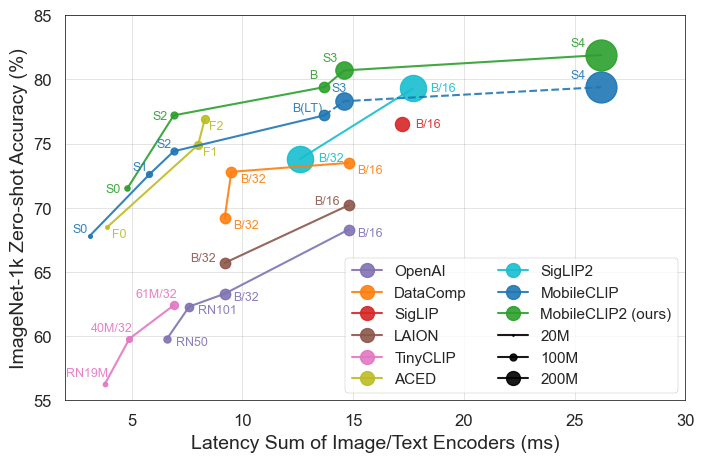
Os resultados falam por si. Os modelos MobileCLIP superam ou igualam consistentemente modelos maiores e mais caros computacionalmente, enquanto rodam significativamente mais rápido em hardware móvel como o iPhone 12 Pro Max.
Principais Destaques do Lançamento
- Eficiência Máxima: O menor modelo,
MobileCLIP-S0, atinge desempenho semelhante ao modelo ViT-B/16 da OpenAI, amplamente utilizado, mas é 4,8x mais rápido e 2,8x menor. - Velocidade de Ponta: O
MobileCLIP2-S4iguala a precisão do poderoso modelo SigLIP-SO400M/14 com metade dos parâmetros e supera o DFN ViT-L/14 com latência 2,5x menor. - Treinamento Inovador: Os modelos são treinados usando uma nova técnica de "Treinamento Reforçado Multimodal" em conjuntos de dados recém-desenvolvidos (DataCompDR e DFNDR), um fator chave em sua eficiência aprimorada.
- Amigável para Desenvolvedores: Os modelos agora são suportados nativamente na popular biblioteca OpenCLIP, facilitando a integração em projetos existentes.
Análise Técnica Profunda
O impressionante desempenho do MobileCLIP decorre de várias inovações importantes:
- Treinamento Reforçado Multimodal: Uma nova estratégia de treinamento que aprimora a capacidade do modelo de conectar imagens e texto de forma eficaz, levando a uma maior precisão com menos recursos.
- Conjuntos de Dados Especialmente Curados: Os modelos foram treinados em
DataCompDReDFNDR, conjuntos de dados massivos gerados em escala especificamente para melhorar a robustez e a eficiência dos modelos de imagem-texto. - Arquiteturas Móveis Eficientes: As torres de visão nos modelos são baseadas em arquiteturas eficientes como o MobileOne, que são otimizadas para alto desempenho em CPUs e GPUs móveis.
Por Que Isso Importa para Desenvolvedores e Consumidores
Ao abrir o código dessas ferramentas, a Apple está capacitando os desenvolvedores a construir recursos sofisticados de IA que antes só eram possíveis com servidores de nuvem poderosos. Isso significa que os aplicativos podem realizar tarefas complexas como reconhecimento de objetos em tempo real, pesquisa visual e legendagem avançada de imagens diretamente no dispositivo do usuário.
Os benefícios para os consumidores são duplos: privacidade e velocidade. O processamento no dispositivo significa que dados sensíveis, como fotos pessoais, nunca precisam sair do telefone. Além disso, as ações são instantâneas, sem o atraso de enviar e receber dados de um servidor. O projeto ainda inclui um aplicativo de demonstração para iOS para mostrar essas capacidades de classificação em tempo real.
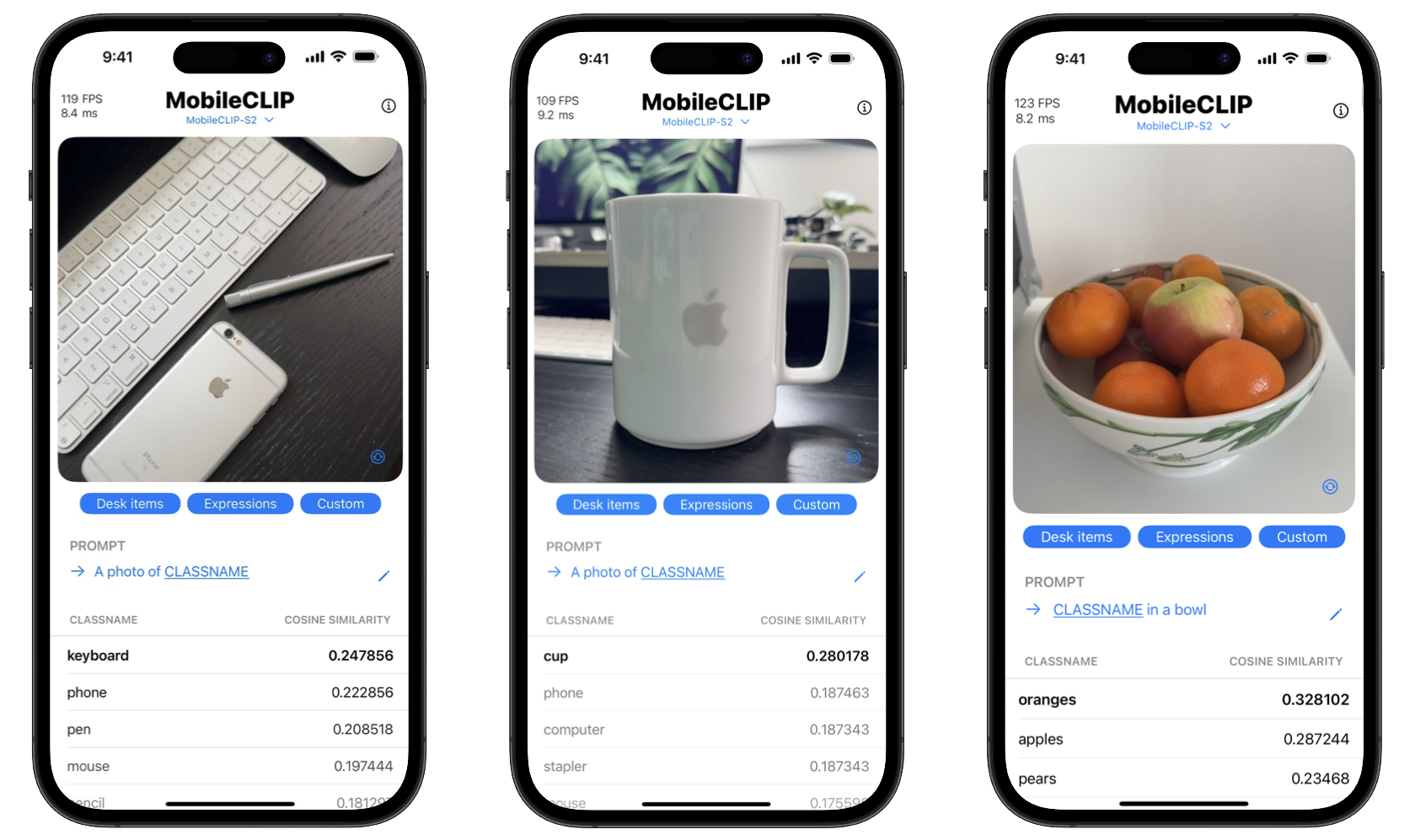
Comece com o MobileCLIP
Os desenvolvedores podem começar a experimentar o MobileCLIP imediatamente. Os modelos estão disponíveis no Hugging Face, e o código-fonte completo, scripts de treinamento e ferramentas de avaliação podem ser encontrados no repositório oficial do GitHub.
Instalação Rápida
conda create -n clipenv python=3.10
conda activate clipenv
pip install -e .