En un movimiento significativo para el panorama de la IA móvil, los investigadores de Apple han abierto el código de MobileCLIP y su potente sucesor, MobileCLIP 2. Estos modelos de imagen-texto están diseñados para ofrecer un rendimiento de clase de escritorio con una eficiencia notable, allanando el camino para una nueva generación de aplicaciones inteligentes, receptivas y privadas en el dispositivo.
El proyecto, detallado en artículos para CVPR 2024 y la prestigiosa revista TMLR, se centra en resolver un desafío crítico en la IA: hacer que los modelos potentes sean lo suficientemente pequeños y rápidos para ejecutarse directamente en dispositivos móviles sin sacrificar la precisión. El conjunto completo de código, modelos preentrenados y conjuntos de datos ya están disponibles para el público en GitHub y Hugging Face.
Rendimiento de un Vistazo
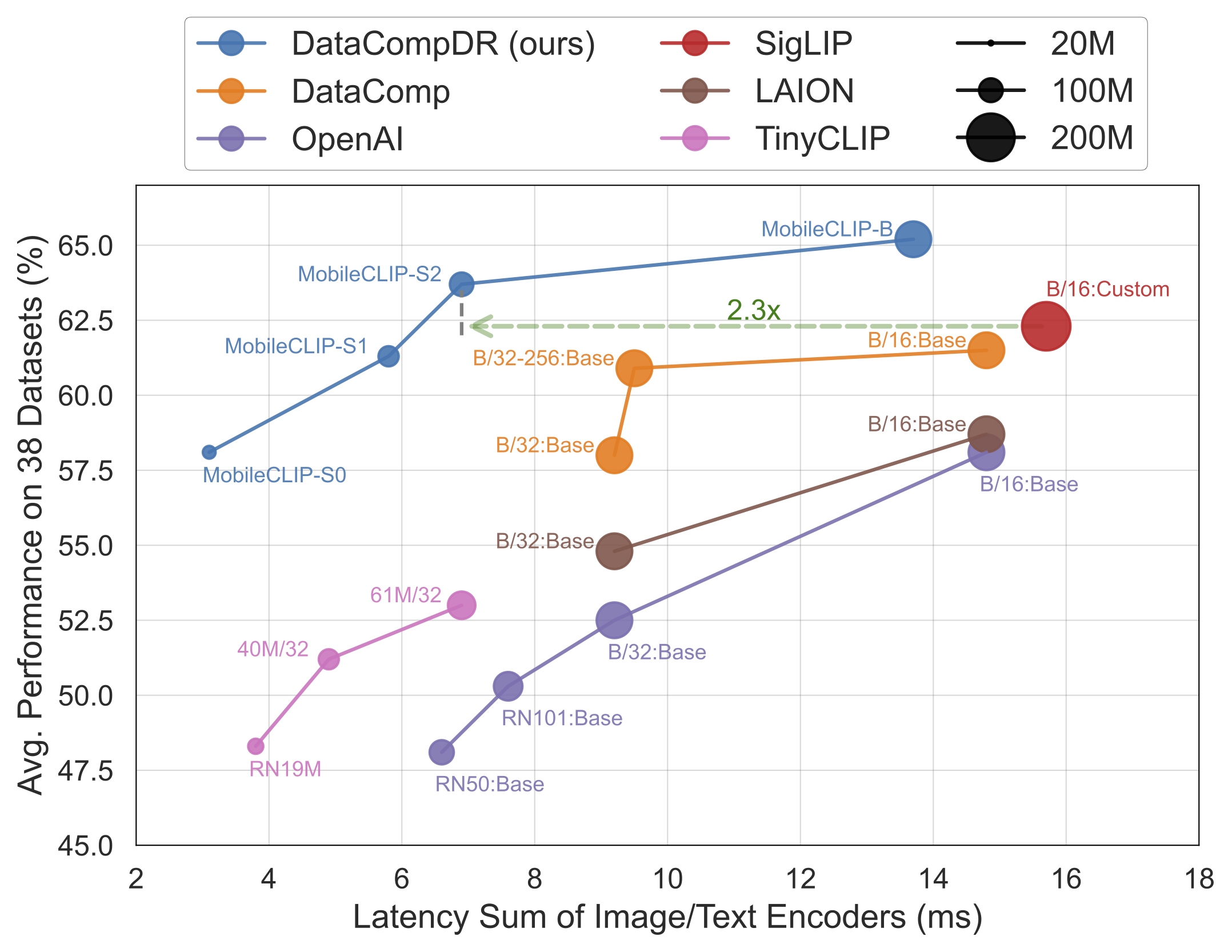
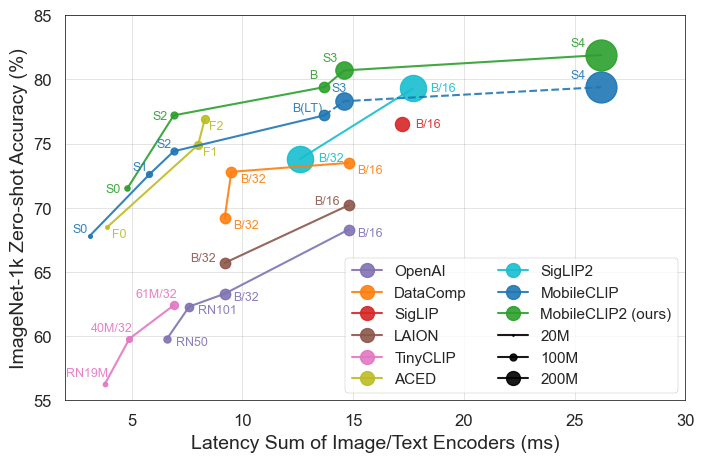
Los resultados hablan por sí solos. Los modelos MobileCLIP superan o igualan consistentemente a modelos más grandes y computacionalmente más caros, mientras se ejecutan significativamente más rápido en hardware móvil como el iPhone 12 Pro Max.
Aspectos Destacados del Lanzamiento
- Máxima Eficiencia: El modelo más pequeño,
MobileCLIP-S0, logra un rendimiento similar al del modelo ViT-B/16 de OpenAI, ampliamente utilizado, pero es 4.8 veces más rápido y 2.8 veces más pequeño. - Velocidad de Vanguardia:
MobileCLIP2-S4iguala la precisión del potente modelo SigLIP-SO400M/14 con la mitad de los parámetros y supera a DFN ViT-L/14 con una latencia 2.5 veces menor. - Entrenamiento Revolucionario: Los modelos se entrenan utilizando una novedosa técnica de "Entrenamiento Reforzado Multimodal" en conjuntos de datos recién desarrollados (DataCompDR y DFNDR), un factor clave en su eficiencia mejorada.
- Fácil para Desarrolladores: Los modelos ahora son compatibles de forma nativa en la popular biblioteca OpenCLIP, lo que facilita su integración en proyectos existentes.
Análisis Técnico Profundo
El impresionante rendimiento de MobileCLIP se debe a varias innovaciones clave:
- Entrenamiento Reforzado Multimodal: Una estrategia de entrenamiento novedosa que mejora la capacidad del modelo para conectar imágenes y texto de manera efectiva, lo que conduce a una mayor precisión con menos recursos.
- Conjuntos de Datos Especialmente Seleccionados: Los modelos fueron entrenados en
DataCompDRyDFNDR, conjuntos de datos masivos generados a escala específicamente para mejorar la robustez и la eficiencia de los modelos de imagen-texto. - Arquitecturas Móviles Eficientes: Las torres de visión en los modelos se basan en arquitecturas eficientes como MobileOne, que están optimizadas para un alto rendimiento en CPU y GPU móviles.
Por Qué Esto es Importante para Desarrolladores y Consumidores
Al abrir el código de estas herramientas, Apple está capacitando a los desarrolladores para crear funciones de IA sofisticadas que antes solo eran posibles con potentes servidores en la nube. Esto significa que las aplicaciones pueden realizar tareas complejas como el reconocimiento de objetos en tiempo real, la búsqueda visual y el subtitulado avanzado de imágenes directamente en el dispositivo de un usuario.
Los beneficios para los consumidores son dobles: privacidad y velocidad. El procesamiento en el dispositivo significa que los datos confidenciales, como las fotos personales, nunca tienen que salir del teléfono. Además, las acciones son instantáneas, sin el retraso de enviar y recibir datos de un servidor. El proyecto incluso incluye una aplicación de demostración para iOS para mostrar estas capacidades de clasificación en tiempo real.
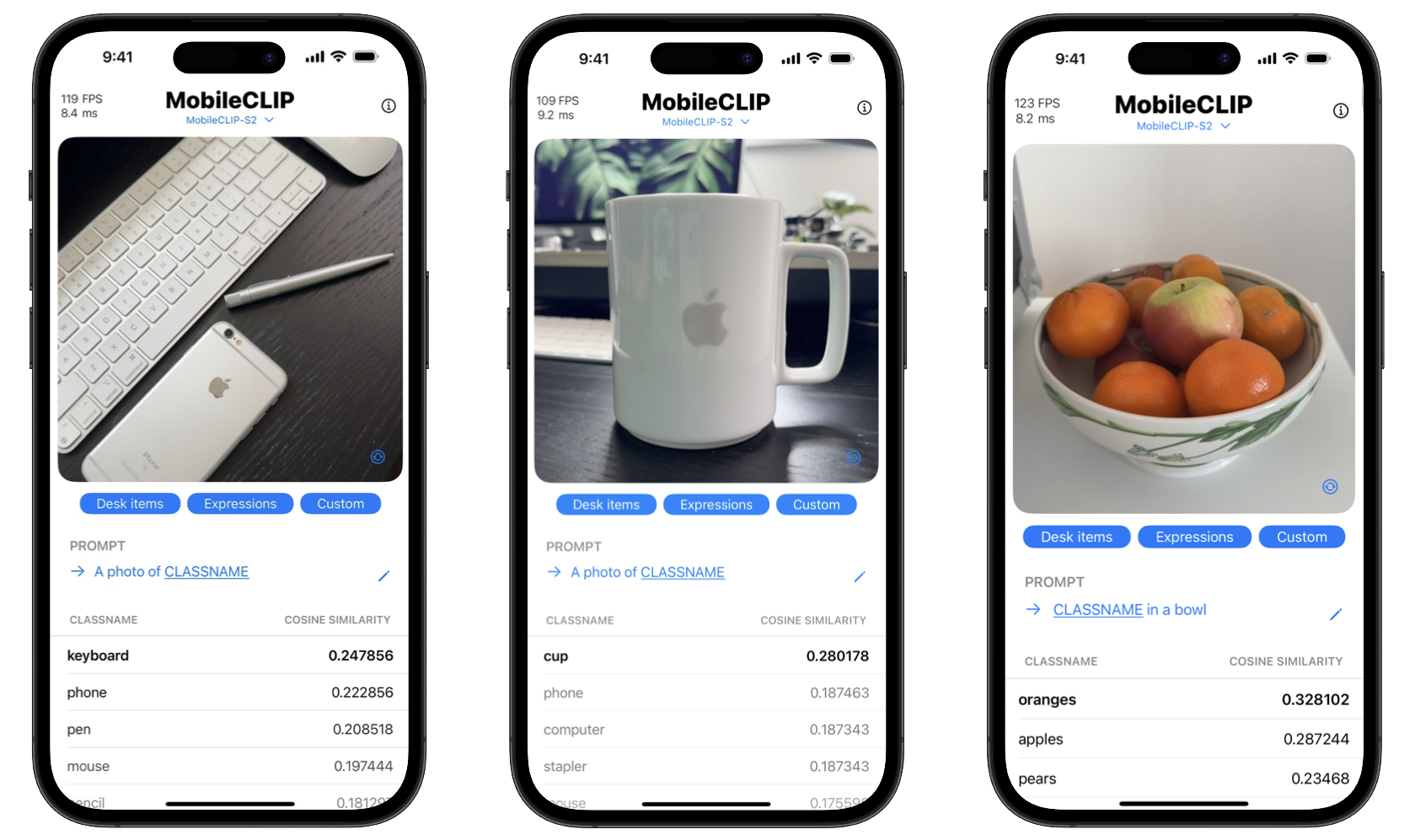
Comienza con MobileCLIP
Los desarrolladores pueden comenzar a experimentar con MobileCLIP de inmediato. Los modelos están disponibles en Hugging Face, y el código fuente completo, los scripts de entrenamiento y las herramientas de evaluación se pueden encontrar en el repositorio oficial de GitHub.
Instalación Rápida
conda create -n clipenv python=3.10
conda activate clipenv
pip install -e .