Dans un mouvement significatif pour le paysage de l'IA mobile, les chercheurs d'Apple ont publié en open source MobileCLIP et son puissant successeur, MobileCLIP 2. Ces modèles image-texte sont conçus pour offrir des performances de classe de bureau avec une efficacité remarquable, ouvrant la voie à une nouvelle génération d'applications intelligentes, réactives et privées sur l'appareil.
Le projet, détaillé dans des articles pour CVPR 2024 et la prestigieuse revue TMLR, se concentre sur la résolution d'un défi critique en IA : rendre les modèles puissants suffisamment petits et rapides pour fonctionner directement sur les appareils mobiles sans sacrifier la précision. La suite complète de code, de modèles pré-entraînés et de jeux de données est maintenant disponible au public sur GitHub et Hugging Face.
Aperçu des performances
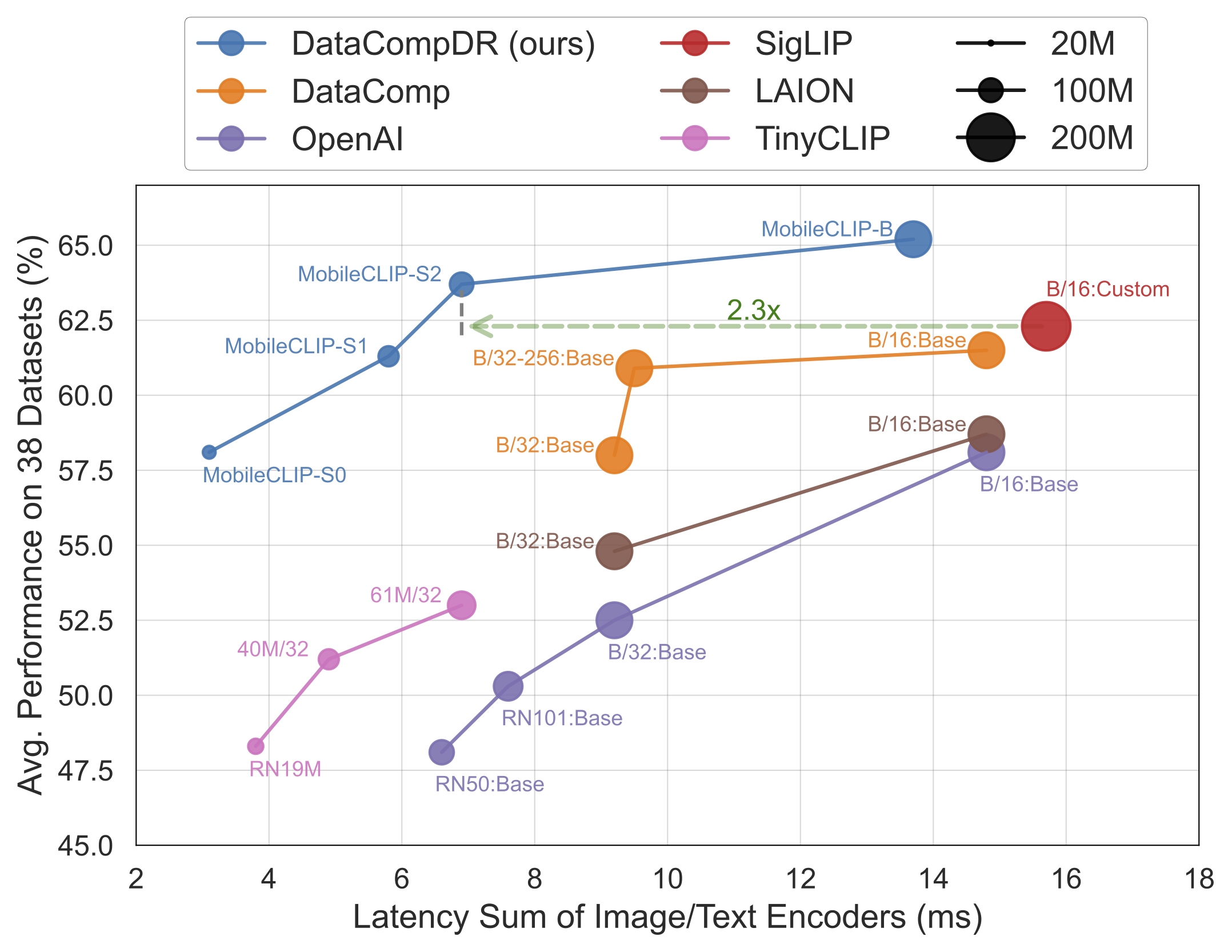
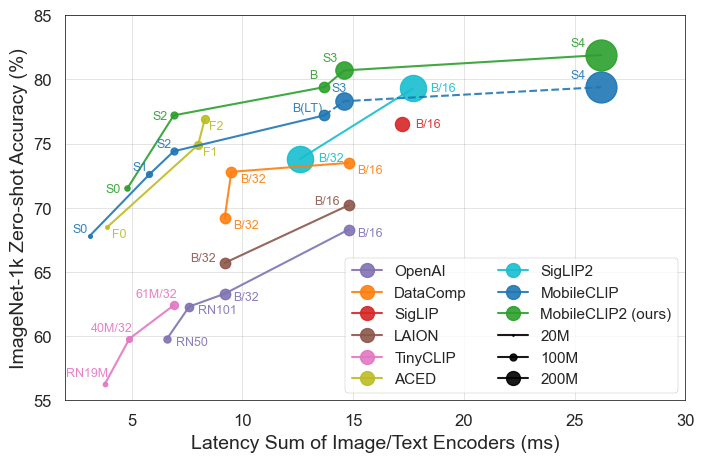
Les résultats parlent d'eux-mêmes. Les modèles MobileCLIP surpassent ou égalent constamment les modèles plus grands et plus coûteux en calcul, tout en fonctionnant beaucoup plus rapidement sur du matériel mobile comme l'iPhone 12 Pro Max.
Points forts de la publication
- Efficacité maximale : Le plus petit modèle,
MobileCLIP-S0, atteint des performances similaires au modèle ViT-B/16 d'OpenAI, largement utilisé, mais il est 4,8x plus rapide et 2,8x plus petit. - Vitesse de pointe :
MobileCLIP2-S4égale la précision du puissant modèle SigLIP-SO400M/14 avec la moitié des paramètres et surpasse le DFN ViT-L/14 avec une latence 2,5x inférieure. - Entraînement révolutionnaire : Les modèles sont entraînés à l'aide d'une nouvelle technique de "Formation renforcée multimodale" sur des jeux de données nouvellement développés (DataCompDR et DFNDR), un facteur clé de leur efficacité améliorée.
- Facile pour les développeurs : Les modèles sont désormais pris en charge nativement dans la populaire bibliothèque OpenCLIP, ce qui les rend faciles à intégrer dans des projets existants.
Analyse technique approfondie
Les performances impressionnantes de MobileCLIP découlent de plusieurs innovations clés :
- Formation renforcée multimodale : Une nouvelle stratégie de formation qui améliore la capacité du modèle à connecter efficacement les images et le texte, conduisant à une plus grande précision avec moins de ressources.
- Jeux de données spécialement sélectionnés : Les modèles ont été entraînés sur
DataCompDRetDFNDR, des jeux de données massifs générés à grande échelle spécifiquement pour améliorer la robustesse et l'efficacité des modèles image-texte. - Architectures mobiles efficaces : Les tours de vision des modèles sont basées sur des architectures efficaces comme MobileOne, qui sont optimisées pour des performances élevées sur les processeurs et les GPU mobiles.
Pourquoi c'est important pour les développeurs et les consommateurs
En publiant ces outils en open source, Apple donne aux développeurs les moyens de créer des fonctionnalités d'IA sophistiquées qui n'étaient auparavant possibles qu'avec de puissants serveurs cloud. Cela signifie que les applications peuvent effectuer des tâches complexes comme la reconnaissance d'objets en temps réel, la recherche visuelle et le sous-titrage avancé d'images directement sur l'appareil d'un utilisateur.
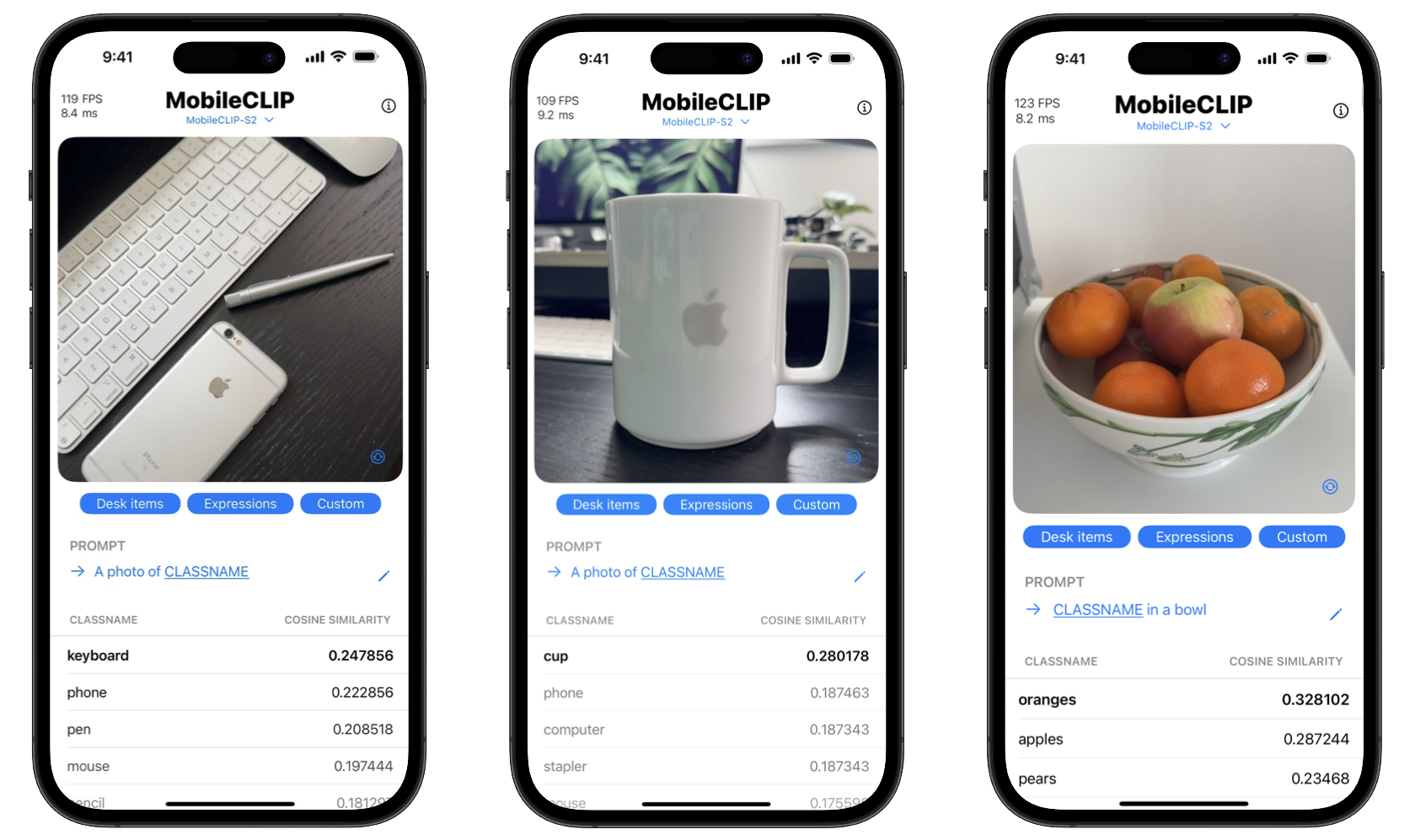
Les avantages pour les consommateurs sont doubles : la confidentialité et la vitesse. Le traitement sur l'appareil signifie que les données sensibles comme les photos personnelles n'ont jamais à quitter le téléphone. De plus, les actions sont instantanées, sans le décalage lié à l'envoi et à la réception de données d'un serveur. Le projet comprend même une application de démonstration iOS pour présenter ces capacités de classification en temps réel.
Commencer avec MobileCLIP
Les développeurs peuvent commencer à expérimenter avec MobileCLIP immédiatement. Les modèles sont disponibles sur Hugging Face, et le code source complet, les scripts d'entraînement et les outils d'évaluation se trouvent dans le dépôt GitHub officiel.
Installation rapide
conda create -n clipenv python=3.10
conda activate clipenv
pip install -e .