In einem bedeutenden Schritt für die mobile KI-Landschaft haben Forscher bei Apple MobileCLIP und seinen leistungsstarken Nachfolger MobileCLIP 2 als Open Source veröffentlicht. Diese Bild-Text-Modelle sind darauf ausgelegt, Leistung auf Desktop-Niveau mit bemerkenswerter Effizienz zu liefern und ebnen den Weg für eine neue Generation intelligenter, reaktionsschneller und privater On-Device-Anwendungen.
Das Projekt, das in Papieren für die CVPR 2024 und das renommierte TMLR-Journal detailliert beschrieben wird, konzentriert sich auf die Lösung einer kritischen Herausforderung in der KI: leistungsstarke Modelle so klein und schnell zu machen, dass sie direkt auf mobilen Geräten laufen, ohne an Genauigkeit einzubüßen. Die gesamte Suite aus Code, vor-trainierten Modellen und Datensätzen ist jetzt öffentlich auf GitHub und Hugging Face verfügbar.
Leistung auf einen Blick
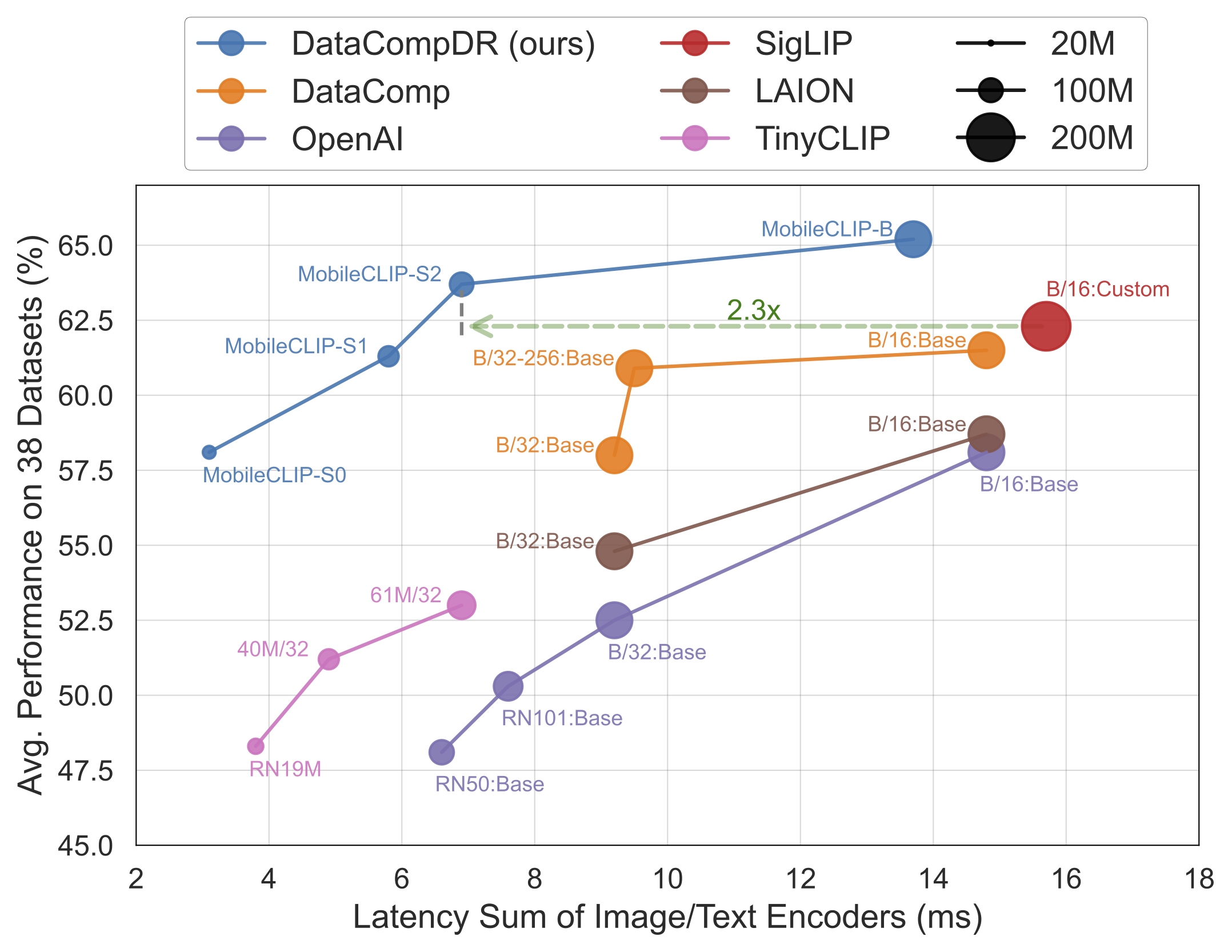
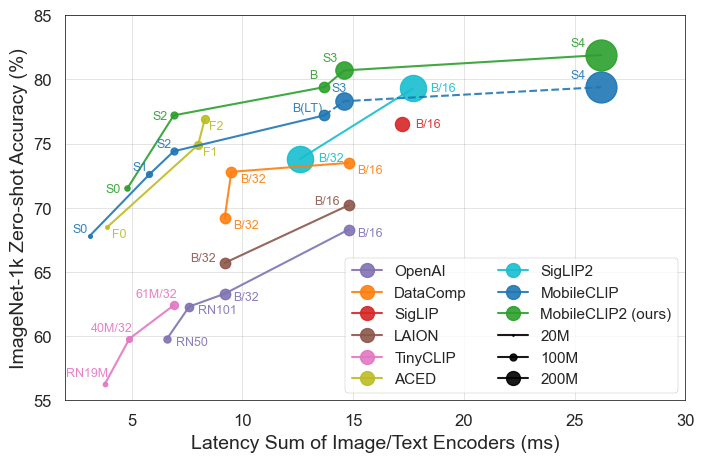
Die Ergebnisse sprechen für sich. MobileCLIP-Modelle übertreffen oder erreichen durchweg die Leistung größerer, rechenintensiverer Modelle, während sie auf mobiler Hardware wie dem iPhone 12 Pro Max deutlich schneller laufen.
Wichtige Highlights der Veröffentlichung
- Spitzeneffizienz: Das kleinste Modell,
MobileCLIP-S0, erreicht eine ähnliche Leistung wie das weit verbreitete ViT-B/16-Modell von OpenAI, ist aber 4,8x schneller und 2,8x kleiner. - Hochmoderne Geschwindigkeit:
MobileCLIP2-S4erreicht die Genauigkeit des leistungsstarken SigLIP-SO400M/14-Modells mit der Hälfte der Parameter und übertrifft DFN ViT-L/14 mit 2,5x geringerer Latenz. - Bahnbrechendes Training: Die Modelle werden mit einer neuartigen "Multi-Modal Reinforced Training"-Technik auf neu entwickelten Datensätzen (DataCompDR und DFNDR) trainiert, ein Schlüsselfaktor für ihre verbesserte Effizienz.
- Entwicklerfreundlich: Die Modelle werden jetzt nativ in der beliebten OpenCLIP-Bibliothek unterstützt, was ihre Integration in bestehende Projekte erleichtert.
Technischer Einblick
Die beeindruckende Leistung von MobileCLIP beruht auf mehreren wichtigen Innovationen:
- Multi-Modal Reinforced Training: Eine neuartige Trainingsstrategie, die die Fähigkeit des Modells verbessert, Bilder und Text effektiv zu verbinden, was zu höherer Genauigkeit bei weniger Ressourcen führt.
- Speziell kuratierte Datensätze: Die Modelle wurden auf
DataCompDRundDFNDRtrainiert, riesige Datensätze, die speziell zur Verbesserung der Robustheit und Effizienz von Bild-Text-Modellen im großen Maßstab generiert wurden. - Effiziente mobile Architekturen: Die Vision Towers in den Modellen basieren auf effizienten Architekturen wie MobileOne, die für hohe Leistung auf mobilen CPUs und GPUs optimiert sind.
Warum dies für Entwickler und Verbraucher wichtig ist
Durch die Veröffentlichung dieser Tools als Open Source ermöglicht Apple Entwicklern, anspruchsvolle KI-Funktionen zu entwickeln, die bisher nur mit leistungsstarken Cloud-Servern möglich waren. Das bedeutet, dass Apps komplexe Aufgaben wie Echtzeit-Objekterkennung, visuelle Suche und erweiterte Bildbeschreibung direkt auf dem Gerät eines Benutzers ausführen können.
Die Vorteile für die Verbraucher sind zweierlei: Datenschutz und Geschwindigkeit. Die Verarbeitung auf dem Gerät bedeutet, dass sensible Daten wie persönliche Fotos das Telefon nie verlassen müssen. Darüber hinaus erfolgen Aktionen sofort, ohne die Verzögerung beim Senden und Empfangen von Daten von einem Server. Das Projekt enthält sogar eine iOS-Demo-App, um diese Echtzeit-Klassifizierungsfähigkeiten zu demonstrieren.
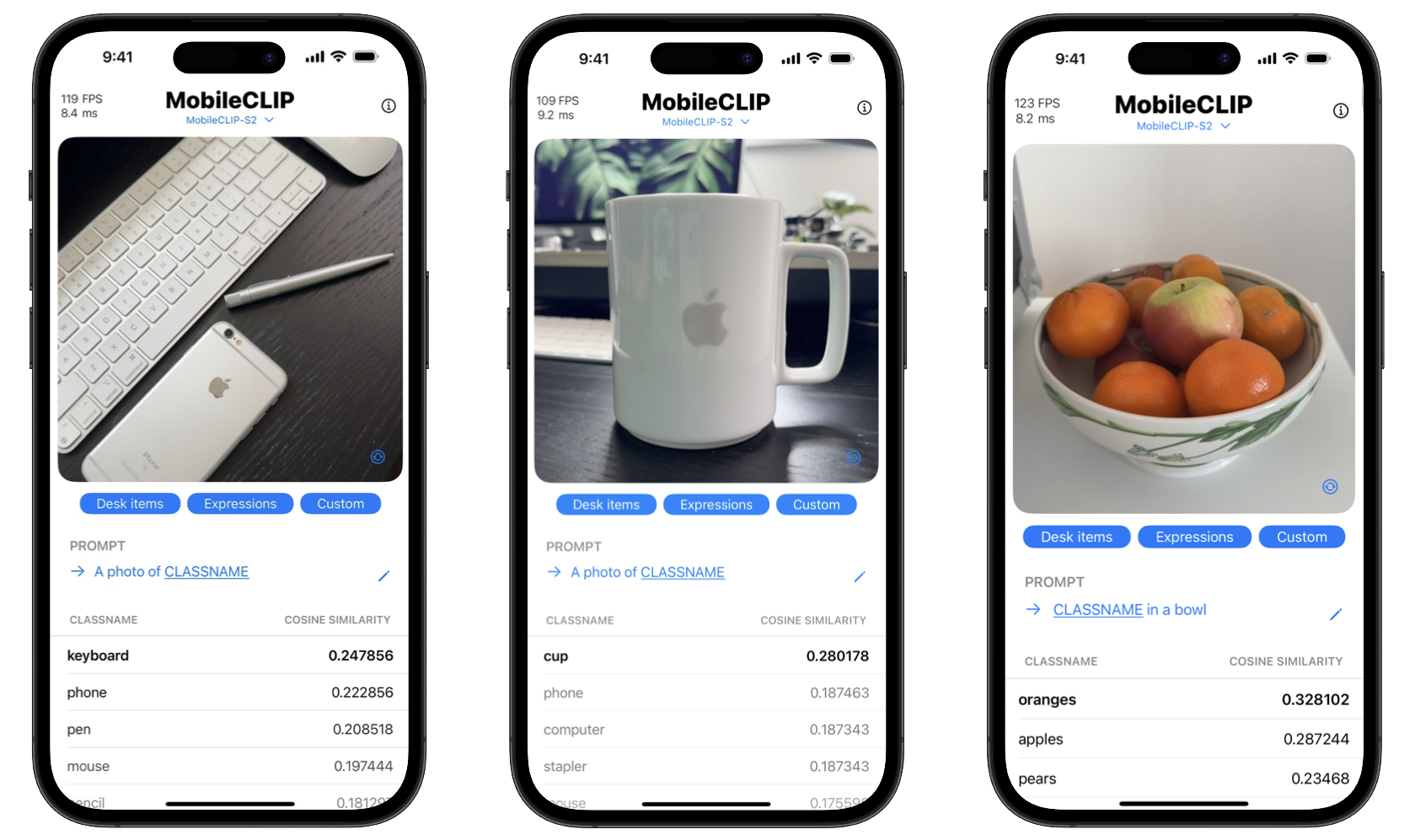
Erste Schritte mit MobileCLIP
Entwickler können sofort mit dem Experimentieren mit MobileCLIP beginnen. Die Modelle sind auf Hugging Face verfügbar, und der vollständige Quellcode, Trainingsskripte und Evaluierungstools finden sich im offiziellen GitHub-Repository.
Schnellinstallation
conda create -n clipenv python=3.10
conda activate clipenv
pip install -e .