它是如何運作的?
看懂圖像
圖像 → Token
Token → 語言
FastVLM 先高效地理解圖像內容,將其轉換為緊湊的標記 (Tokens),然後利用這些標記快速生成準確的文本描述或回答。
核心優勢
極速響應
首 Token 輸出速度驚人!FastVLM-0.5B 比 LLaVA-OneVision 快 85 倍。FastVLM-7B (結合 Qwen2) 比 Cambrian-1-8B 快 7.9 倍 (同等精度)。
小巧高效
模型體積小,部署更輕鬆。FastVLM-0.5B 比 LLaVA-OneVision 小 3.4 倍。非常適合 iPhone、iPad、Mac 等終端裝置。
終端智能
無需依賴雲端,直接在您的蘋果裝置上運行,保護隱私,響應更快。
完美適配 iOS/Mac 生態,賦能邊緣 AI 應用。
範例展示
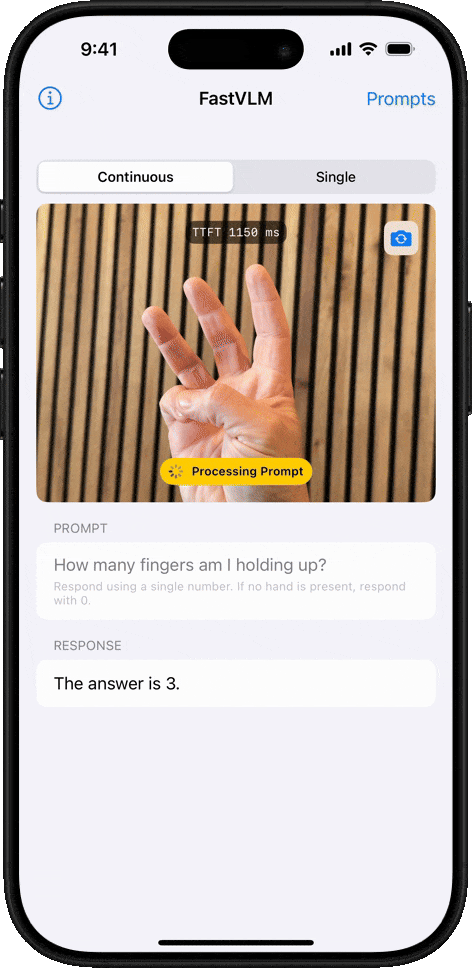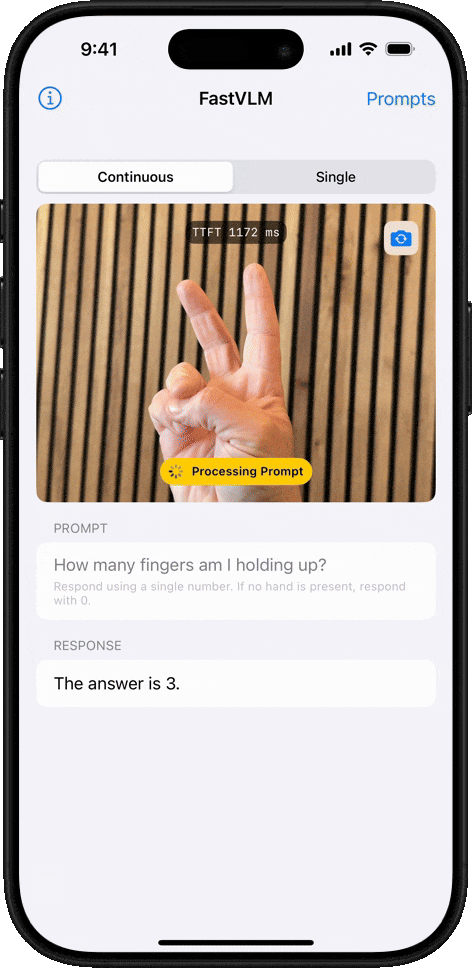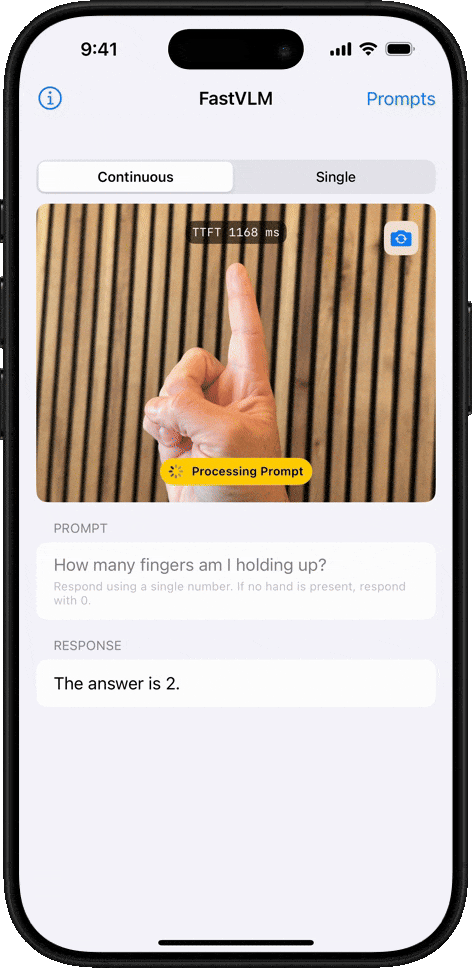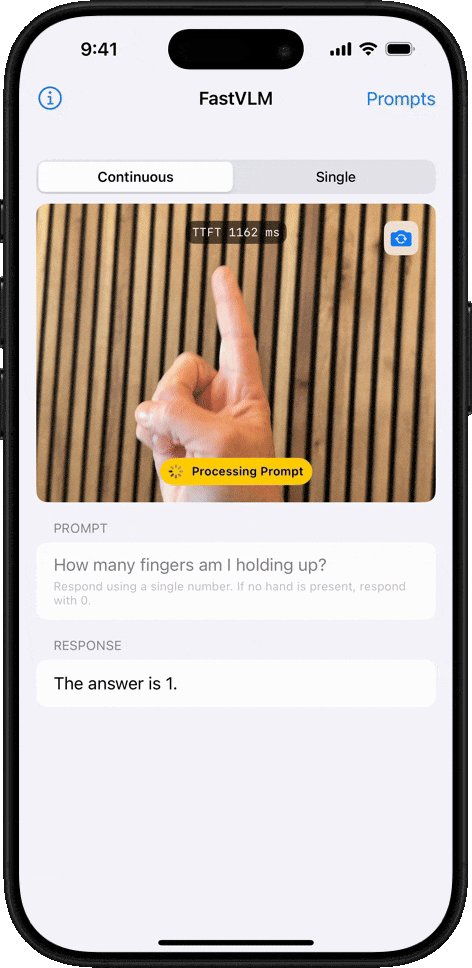
物體計數
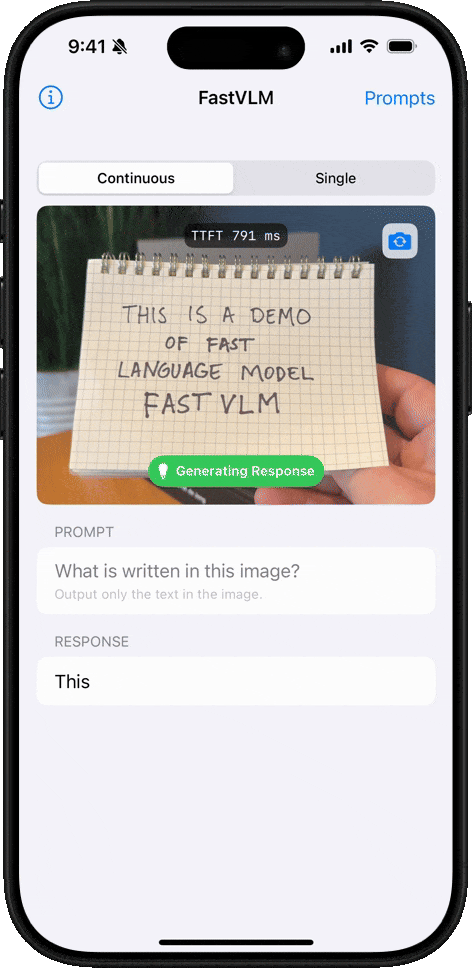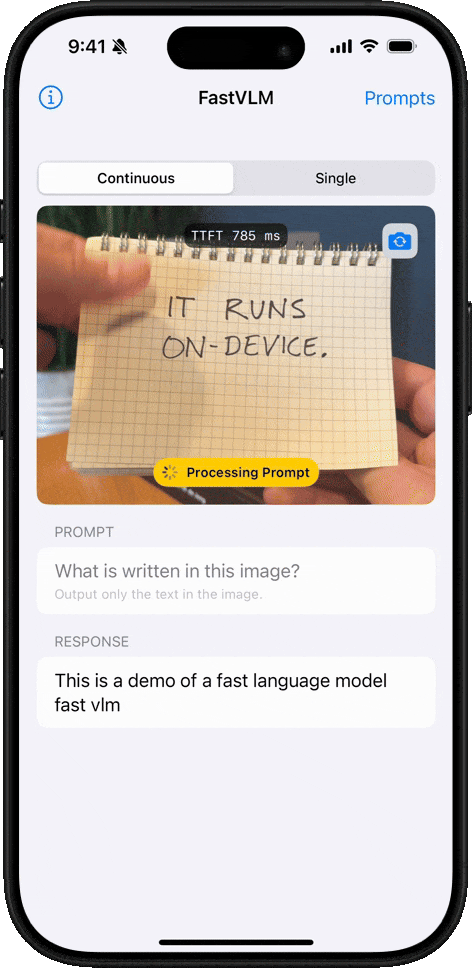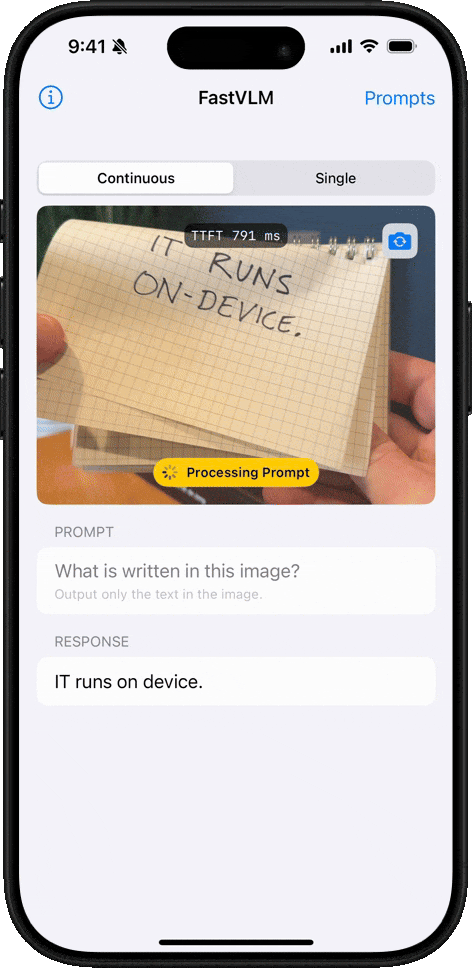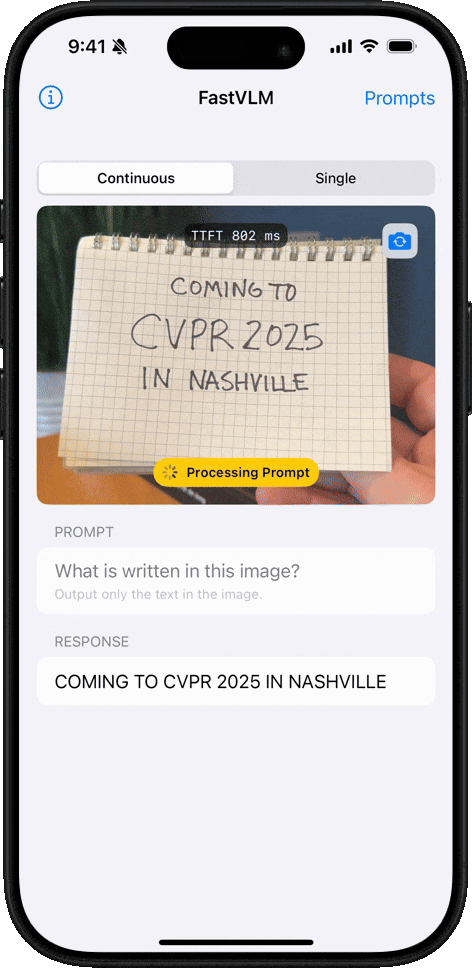
手寫文字識別
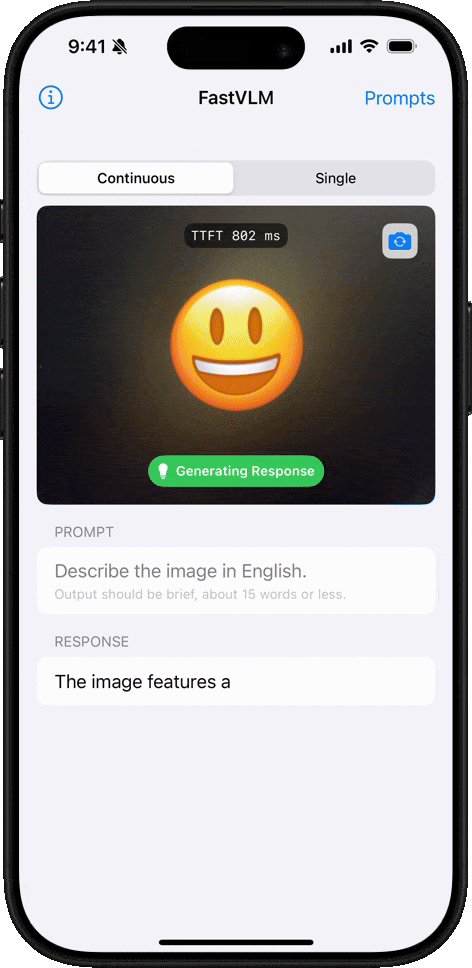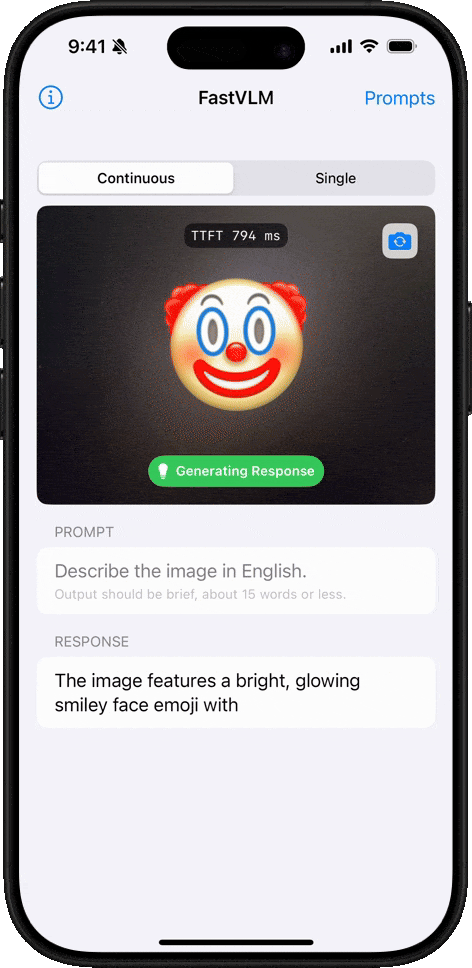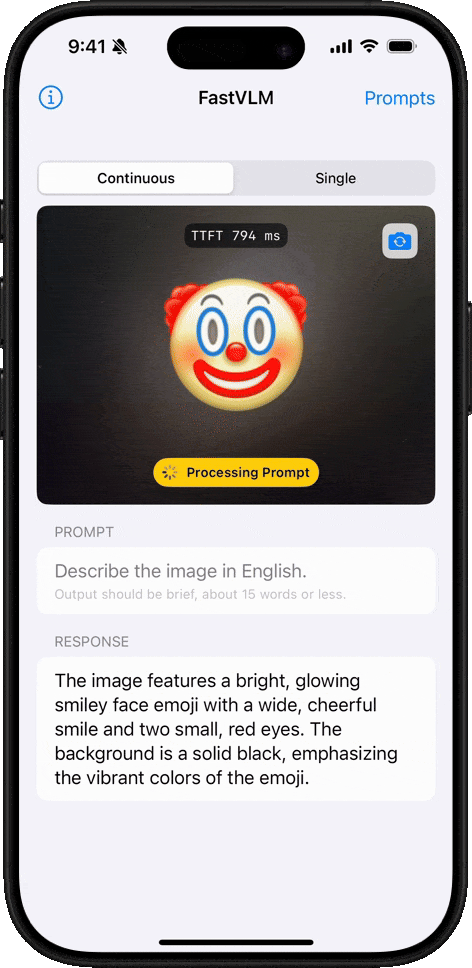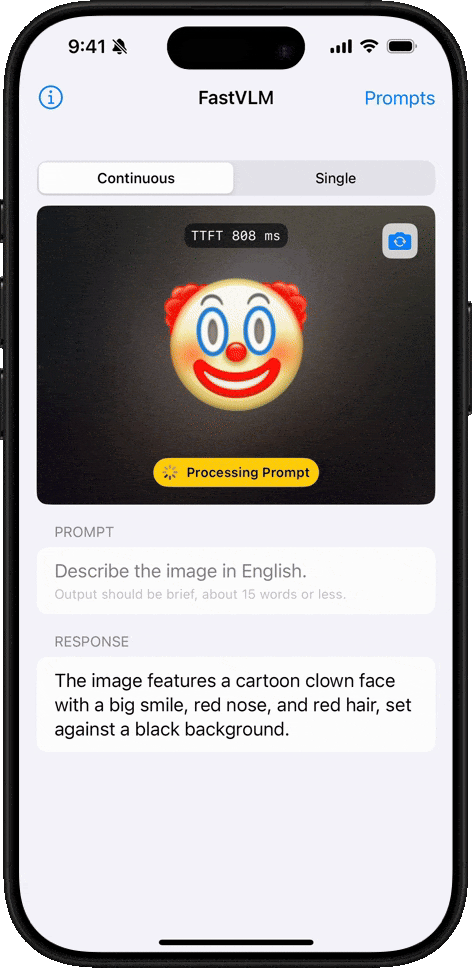
Emoji 理解
效能比較
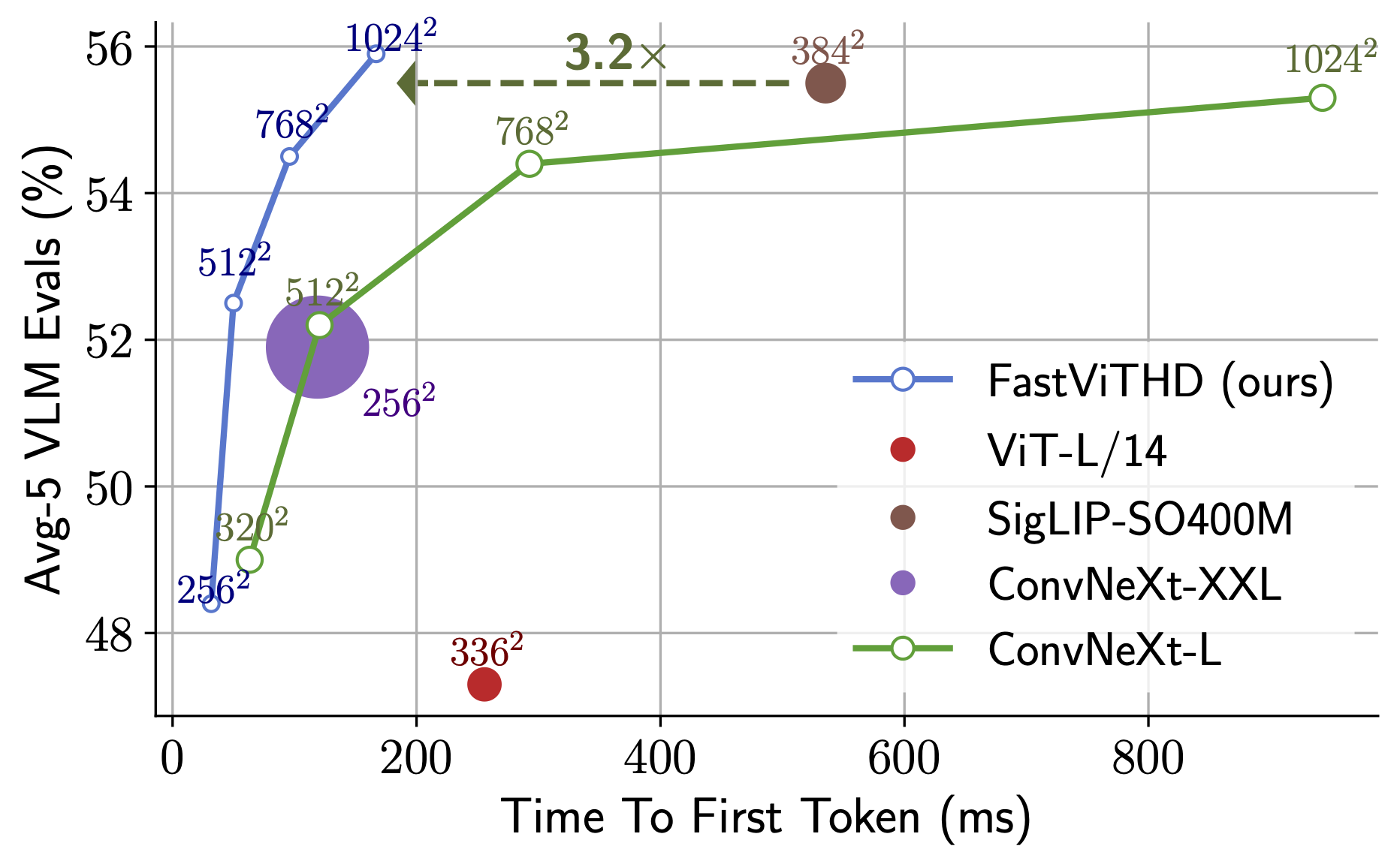
應用場景
圖像描述生成
自動為圖片生成生動、準確的文字描述。
視覺問答 (VQA)
理解圖片內容,並回答關於圖片的提問。
圖像識別與分析
識別圖中的物體、文字或數據,進行智能分析。
特別適合需要即時處理圖像和文本互動的場景。
模型下載
PyTorch Checkpoints
| 模型 (Model) | 階段 (Stage) | 下載連結 (Download Link) |
|---|---|---|
| FastVLM-0.5B | 2 | fastvlm_0.5b_stage2 |
| FastVLM-0.5B | 3 | fastvlm_0.5b_stage3 |
| FastVLM-1.5B | 2 | fastvlm_1.5b_stage2 |
| FastVLM-1.5B | 3 | fastvlm_1.5b_stage3 |
| FastVLM-7B | 2 | fastvlm_7b_stage2 |
| FastVLM-7B | 3 | fastvlm_7b_stage3 |