仕組みは?
画像を理解
画像 → トークン
トークン → 言語
FastVLMは効率的に画像の内容を理解し、コンパクトなトークンに変換し、これらのトークンを使用して正確なテキスト説明や回答を迅速に生成します。
主な利点
超高速応答
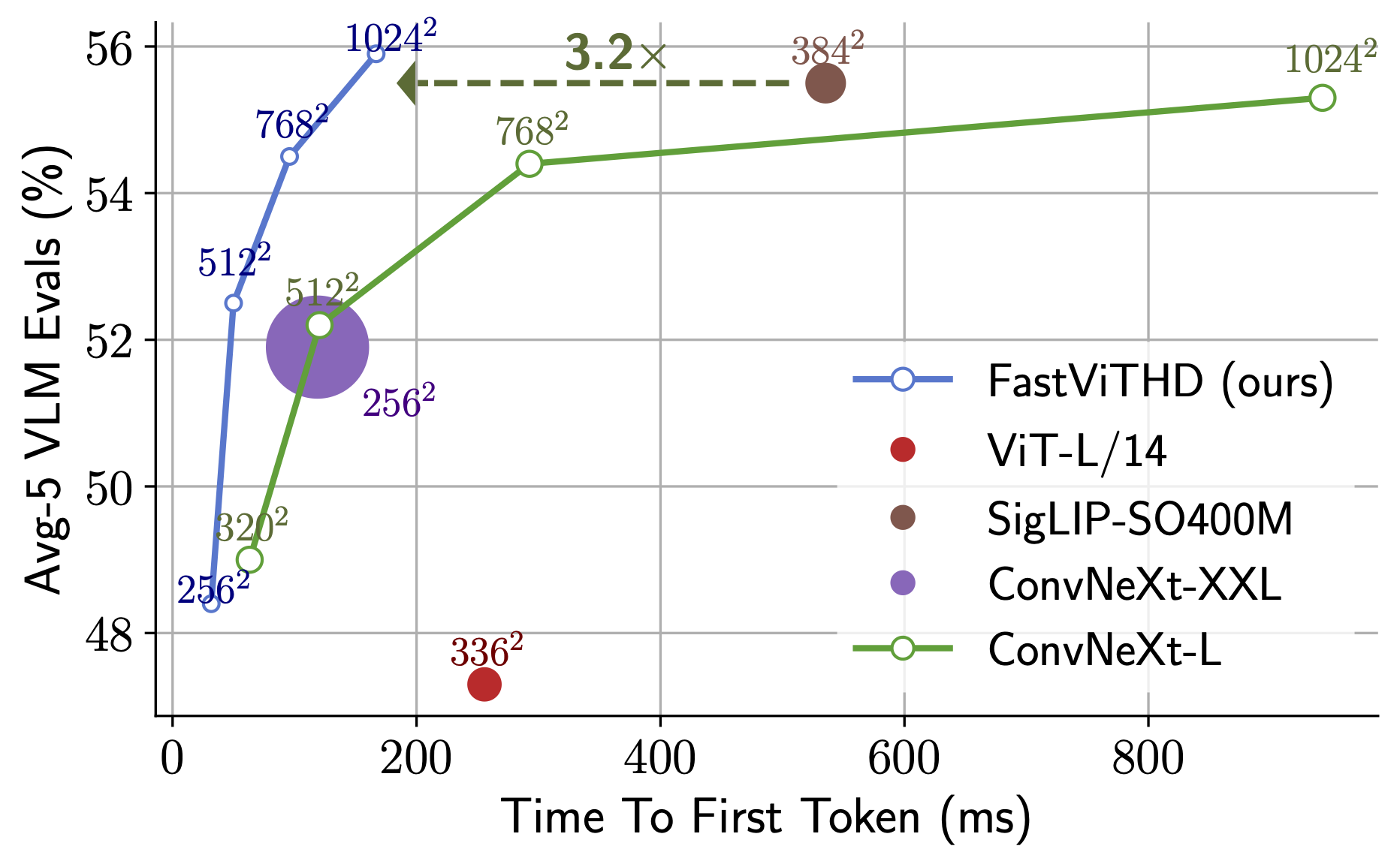
驚異的な初回トークン出力速度!FastVLM-0.5BはLLaVA-OneVisionより85倍高速です。FastVLM-7B(Qwen2と組み合わせ)はCambrian-1-8Bより7.9倍高速です(同等の精度で)。
小型で効率的
モデルサイズが小さく、デプロイが容易。FastVLM-0.5BはLLaVA-OneVisionより3.4倍小さいです。iPhone、iPad、Macなどのデバイスでの使用に最適です。
オンデバイスインテリジェンス
クラウドへの依存なし、Appleデバイスで直接実行し、プライバシーを保護し、より高速に応答します。
iOS/Macエコシステムに完全に適合し、エッジAIアプリケーションを強化します。
使用例
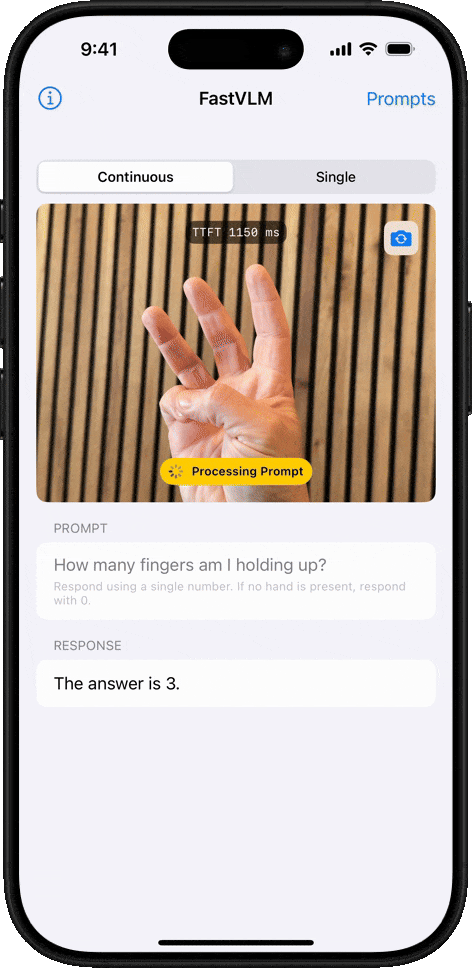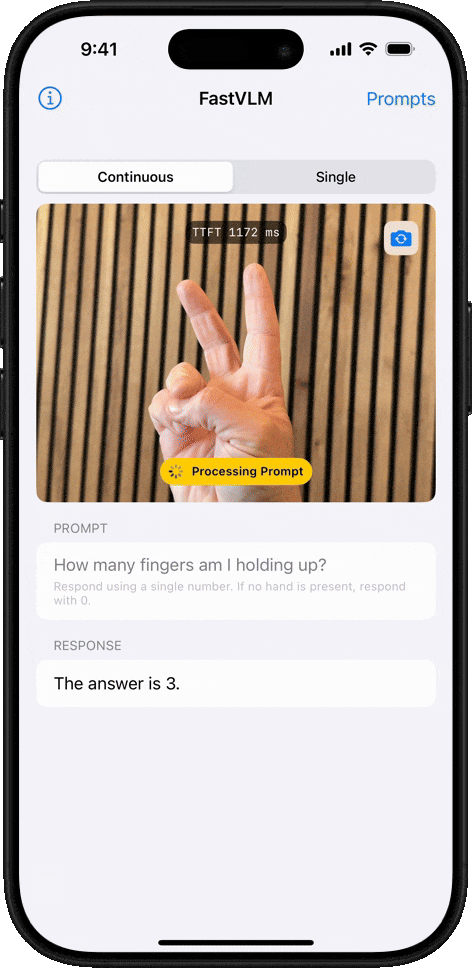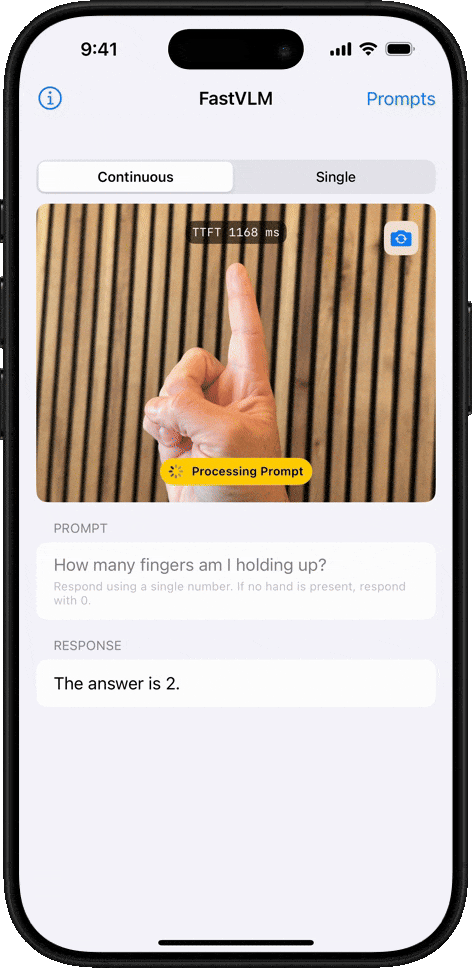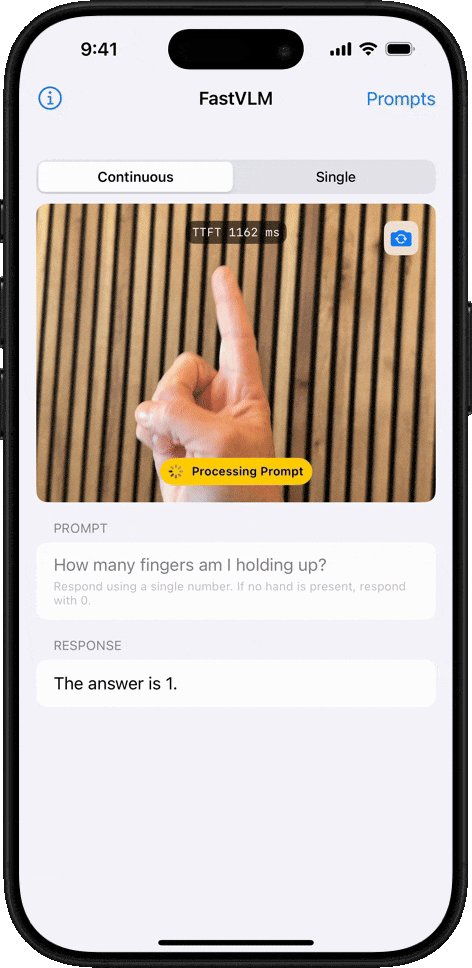
オブジェクトカウント
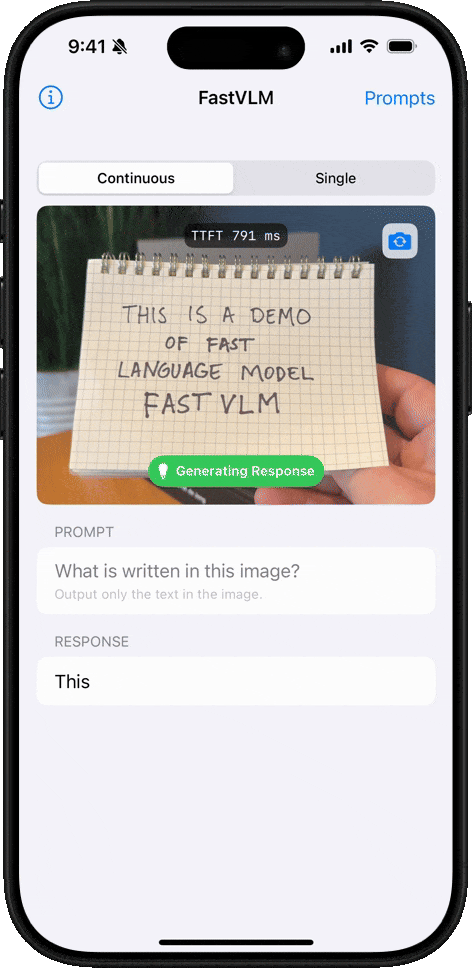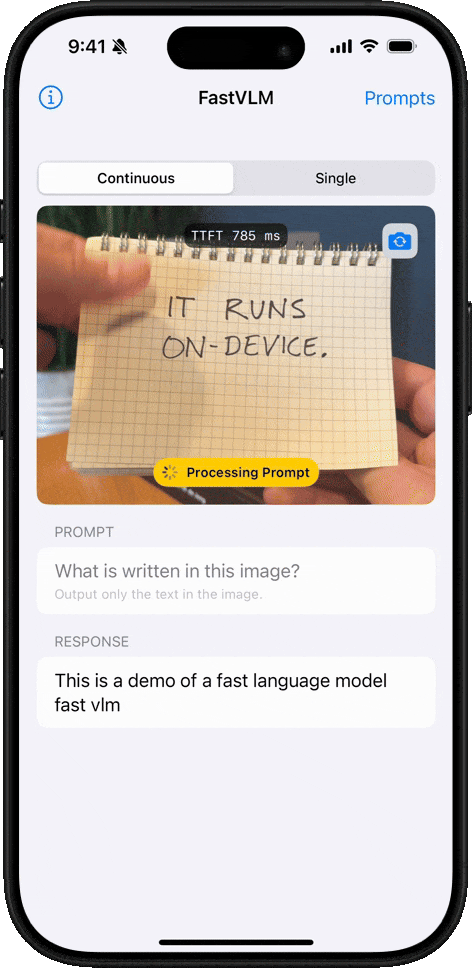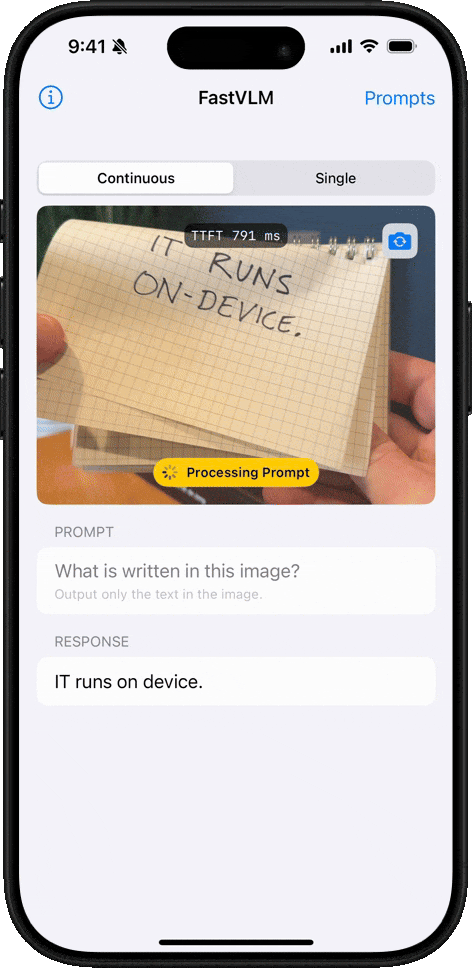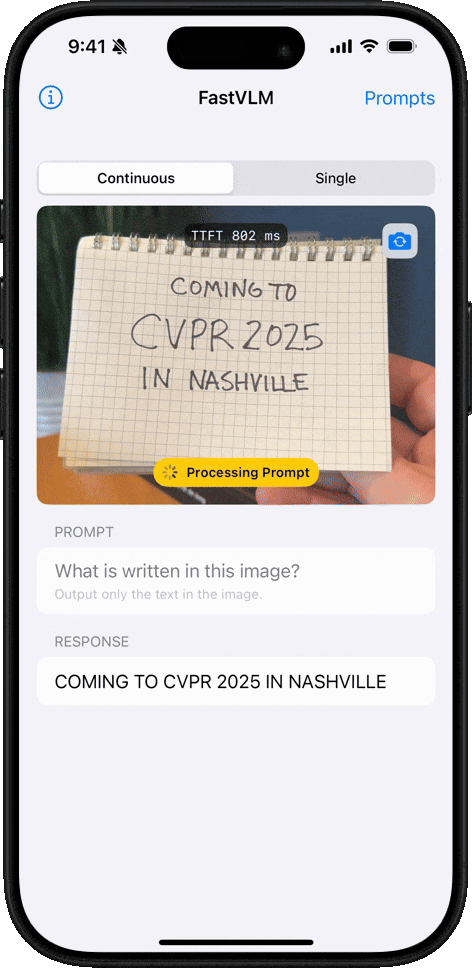
手書き認識
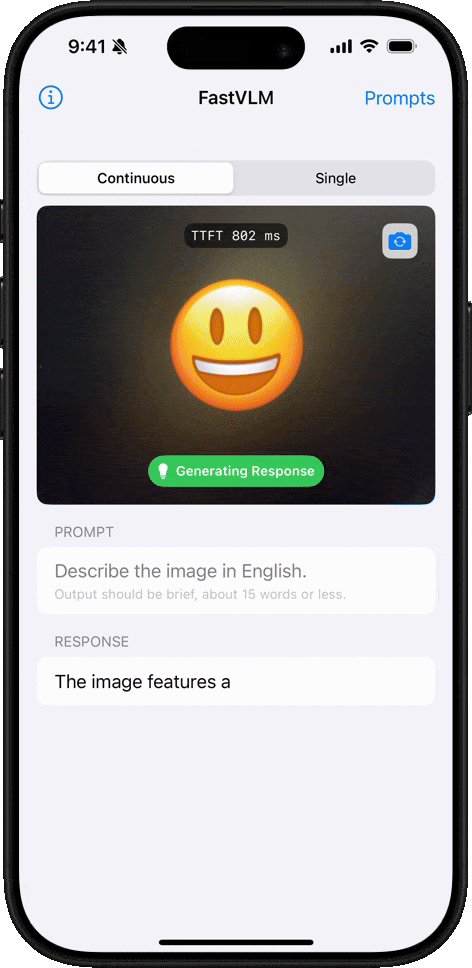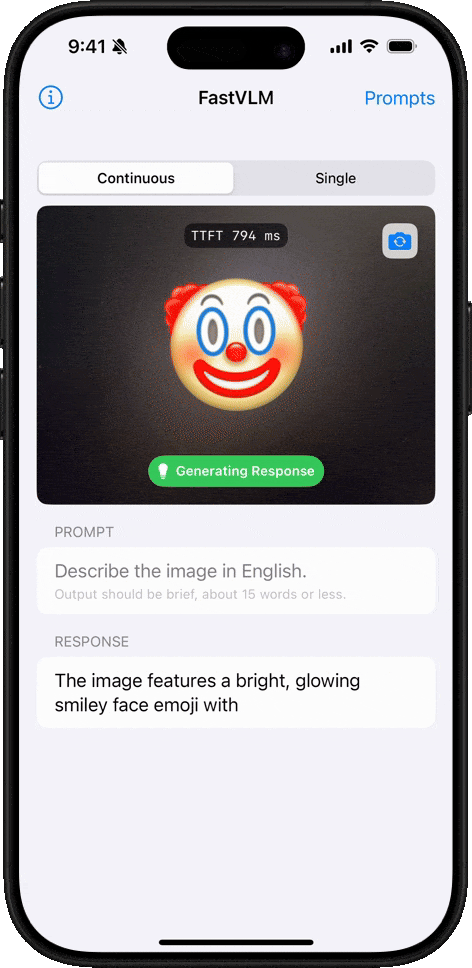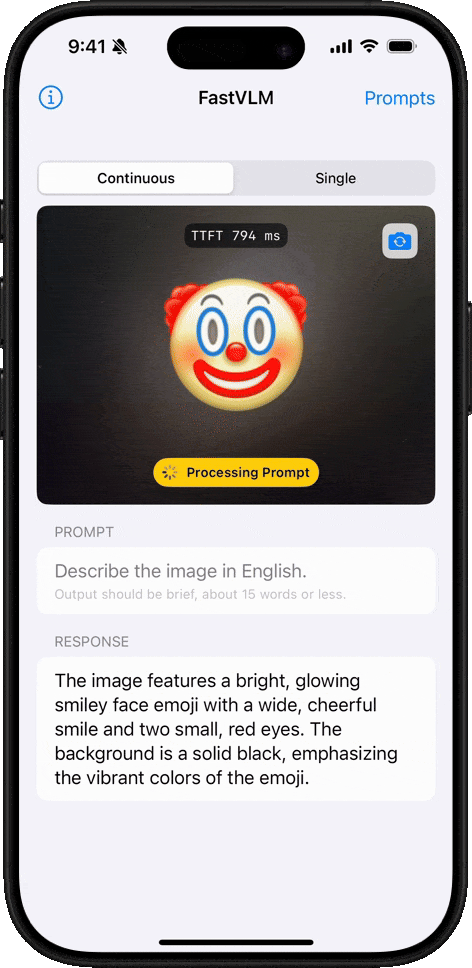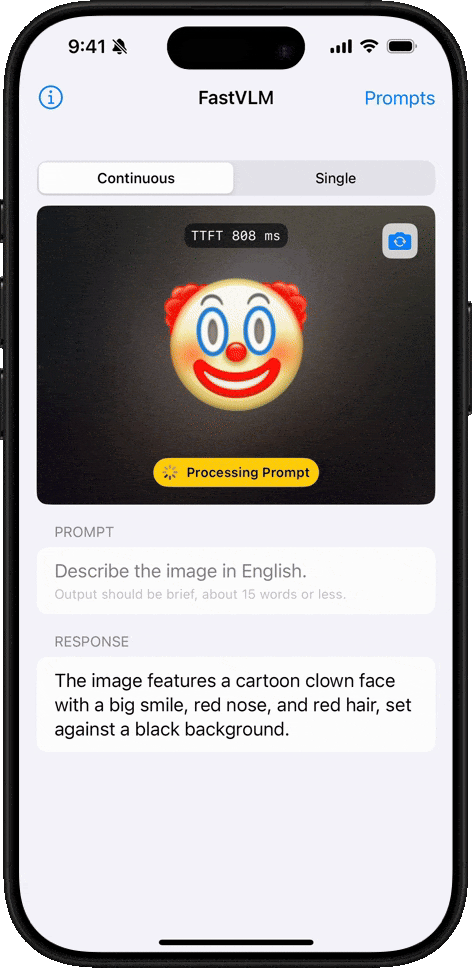
絵文字理解
性能比較
応用シナリオ
画像キャプション生成
画像に対して鮮やかで正確なテキスト説明を自動生成します。
視覚的質問応答(VQA)
画像の内容を理解し、画像に関する質問に答えます。
画像認識と分析
インテリジェントな分析のために、画像内のオブジェクト、テキスト、またはデータを認識します。
リアルタイムの画像とテキストのインタラクションが必要なシナリオに特に適しています。
モデルのダウンロード
PyTorch チェックポイント
| モデル | ステージ | ダウンロードリンク |
|---|---|---|
| FastVLM-0.5B | 2 | fastvlm_0.5b_stage2 |
| FastVLM-0.5B | 3 | fastvlm_0.5b_stage3 |
| FastVLM-1.5B | 2 | fastvlm_1.5b_stage2 |
| FastVLM-1.5B | 3 | fastvlm_1.5b_stage3 |
| FastVLM-7B | 2 | fastvlm_7b_stage2 |
| FastVLM-7B | 3 | fastvlm_7b_stage3 |