¿Cómo funciona?
FastVLM comprende eficientemente el contenido de la imagen, lo convierte en tokens compactos y luego utiliza estos tokens para generar rápidamente descripciones de texto o respuestas precisas.
Ventajas Principales
Velocidad Extrema
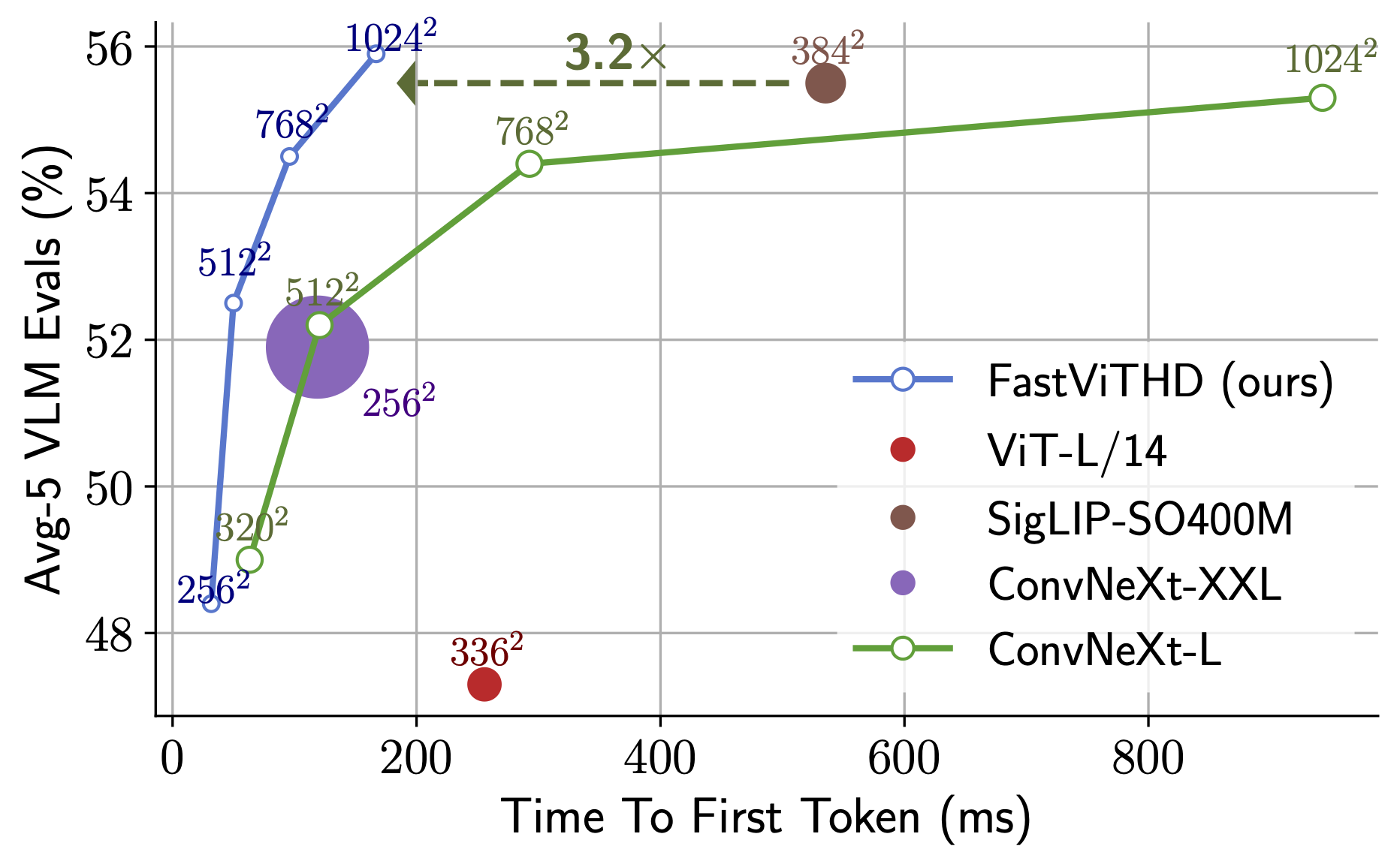
¡Asombrosa velocidad de salida del primer token! FastVLM-0.5B es 85 veces más rápido que LLaVA-OneVision. FastVLM-7B (con Qwen2) es 7.9 veces más rápido que Cambrian-1-8B (con precisión similar).
Compacto y Eficiente
Tamaño de modelo pequeño, implementación más fácil. FastVLM-0.5B es 3.4 veces más pequeño que LLaVA-OneVision. Ideal para uso en el dispositivo como iPhone, iPad, Mac.
Inteligencia en el Dispositivo
Sin dependencia de la nube, se ejecuta directamente en tu dispositivo Apple, protegiendo la privacidad y respondiendo más rápido.
Perfectamente adaptado al ecosistema iOS/Mac, potenciando las aplicaciones de IA en el borde.
Ejemplos Destacados
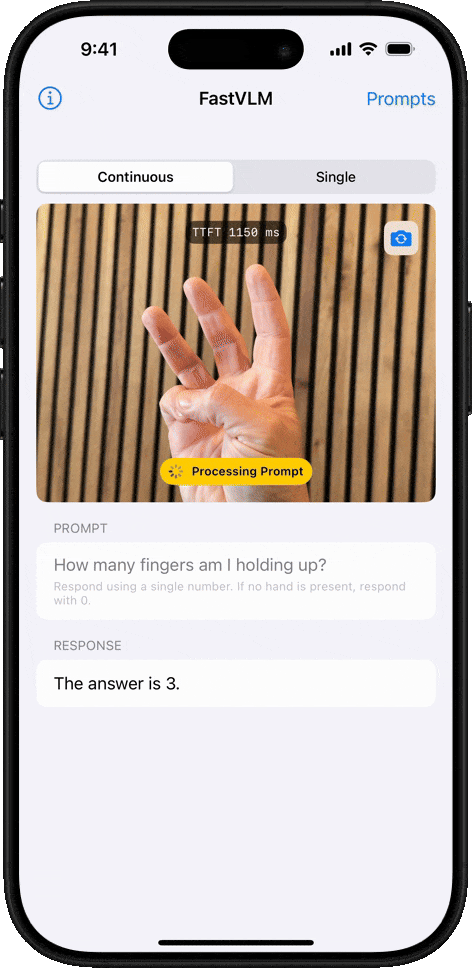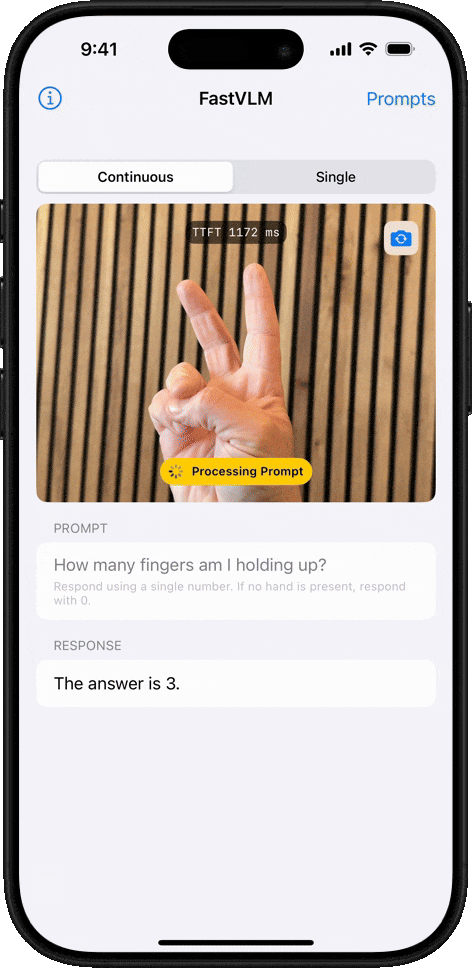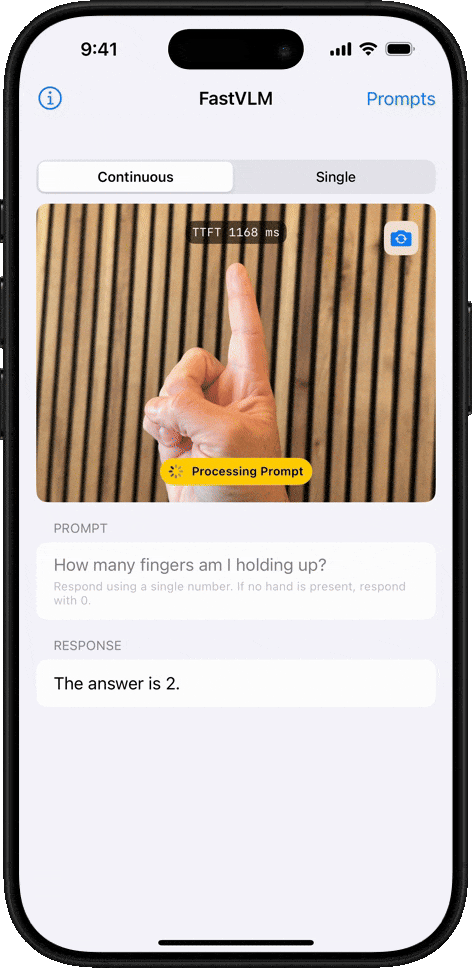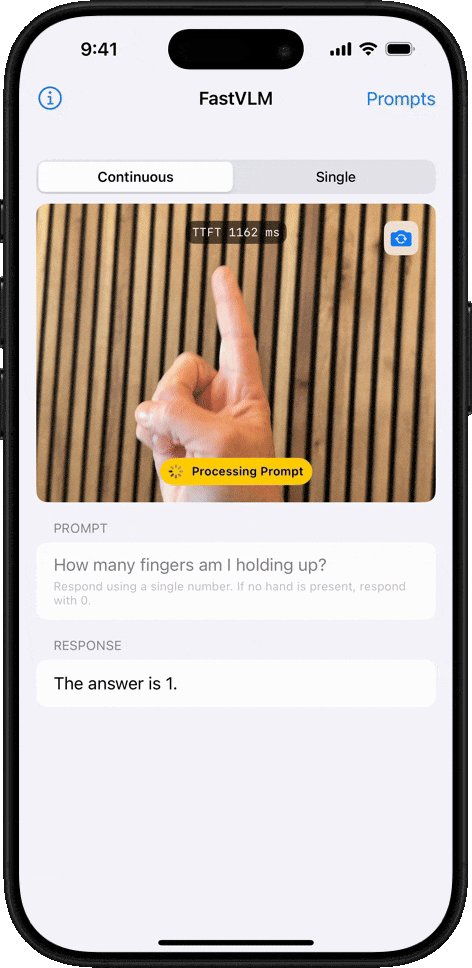
Conteo de Objetos
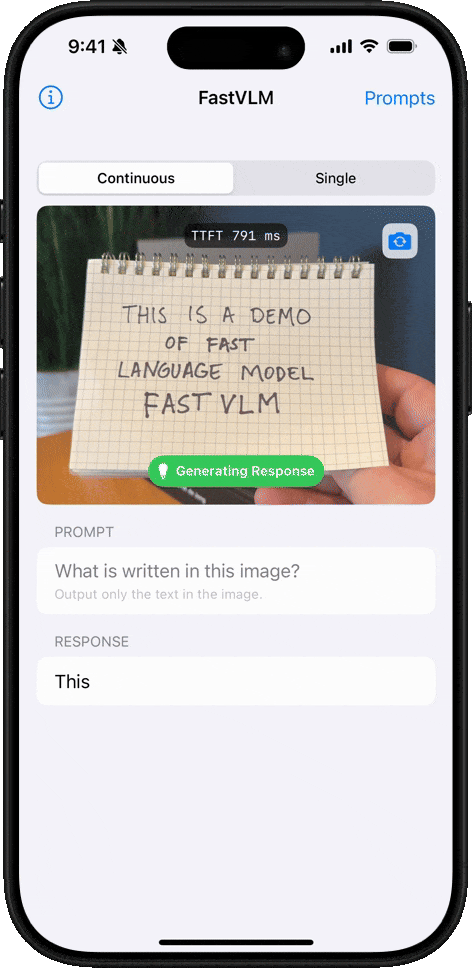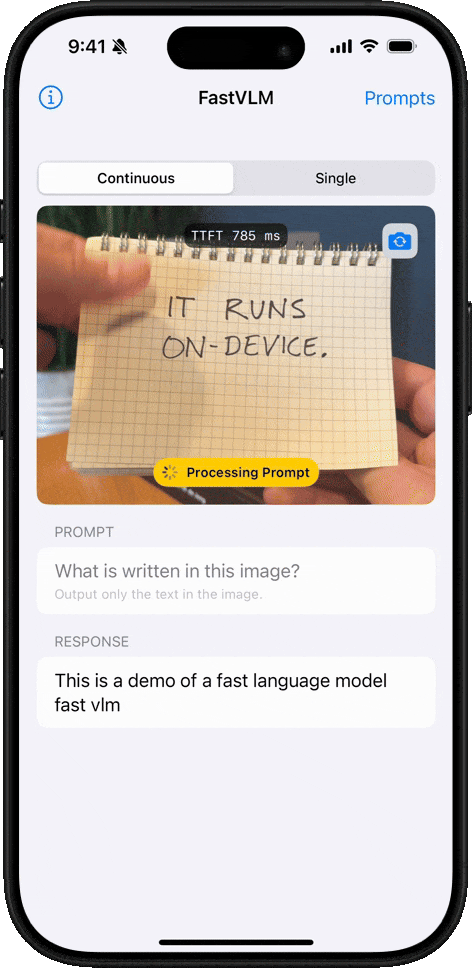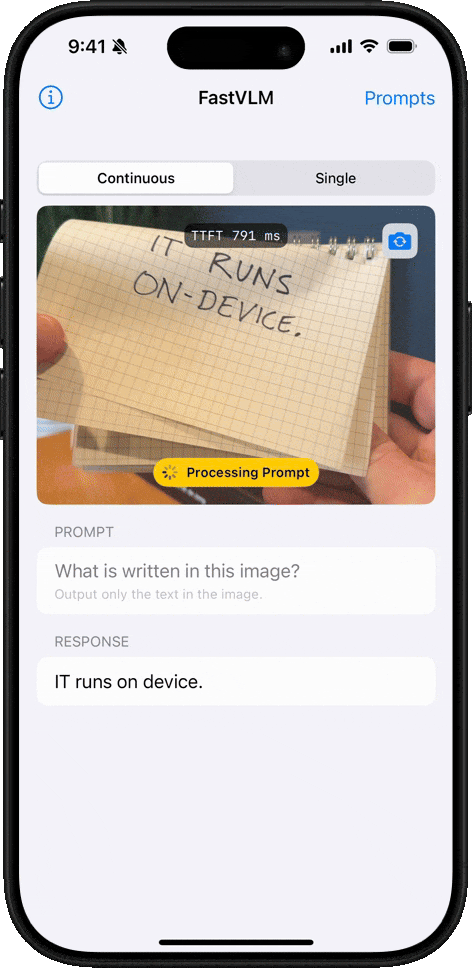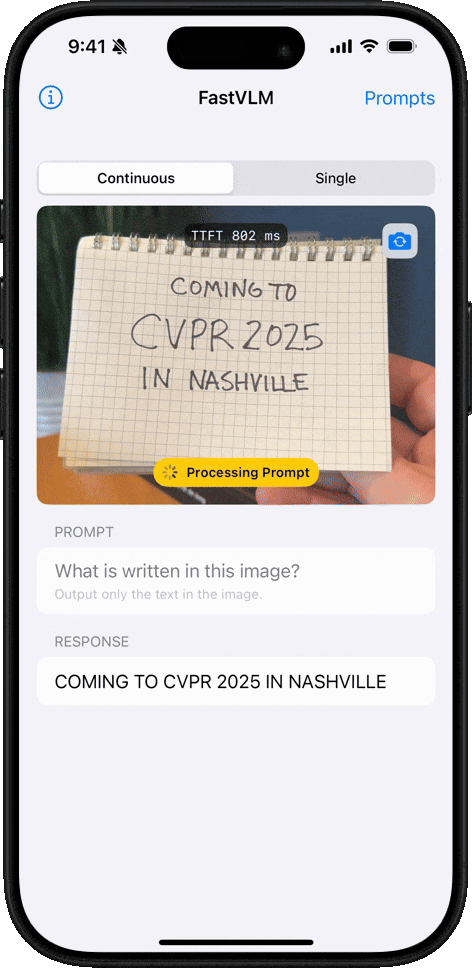
Reconocimiento de Escritura a Mano
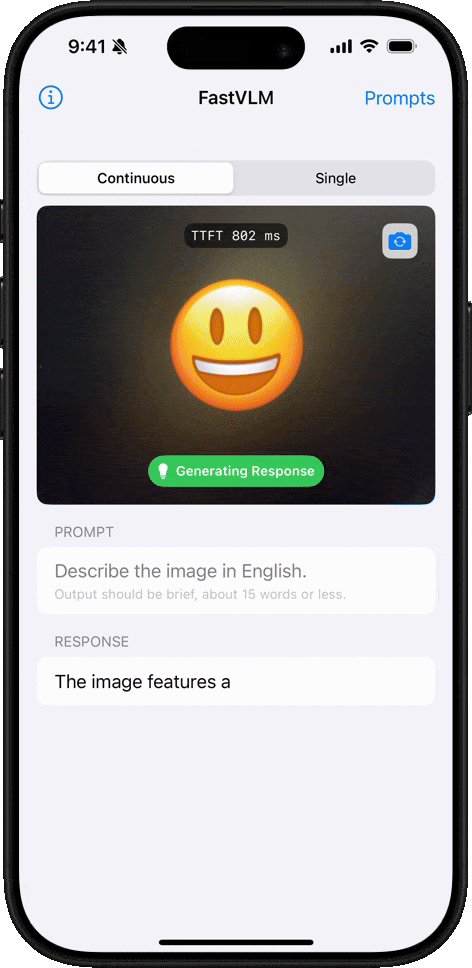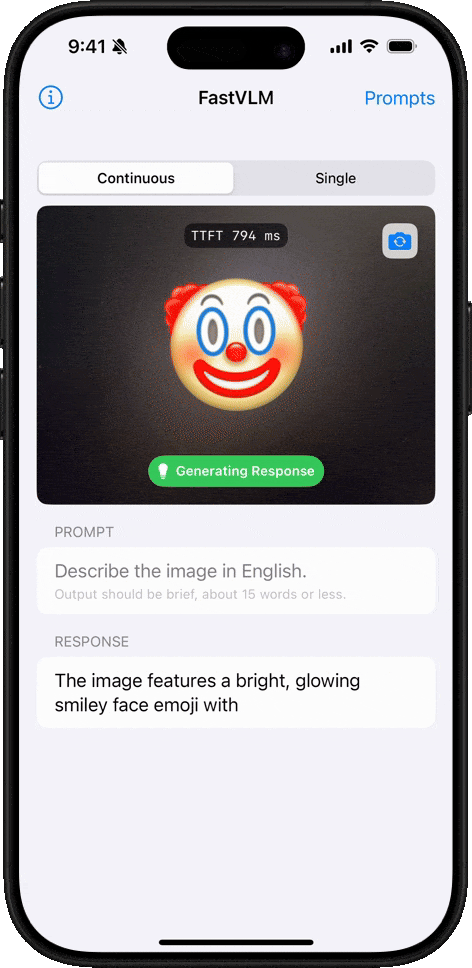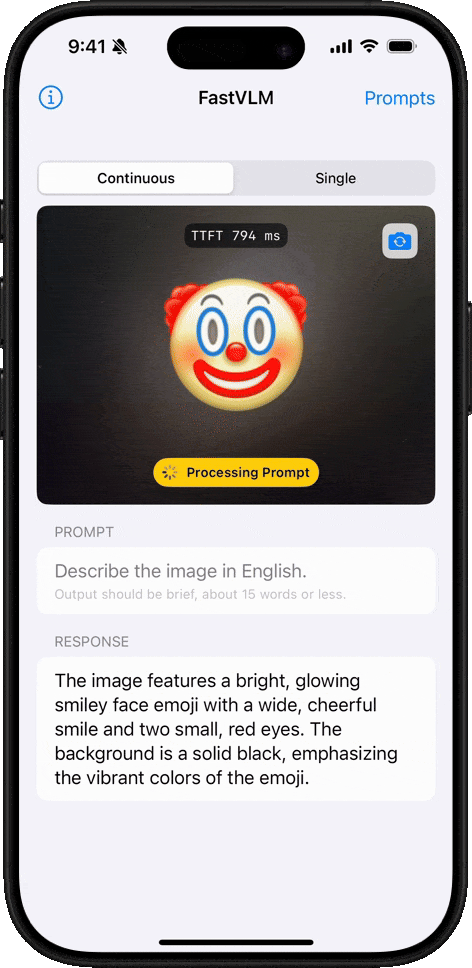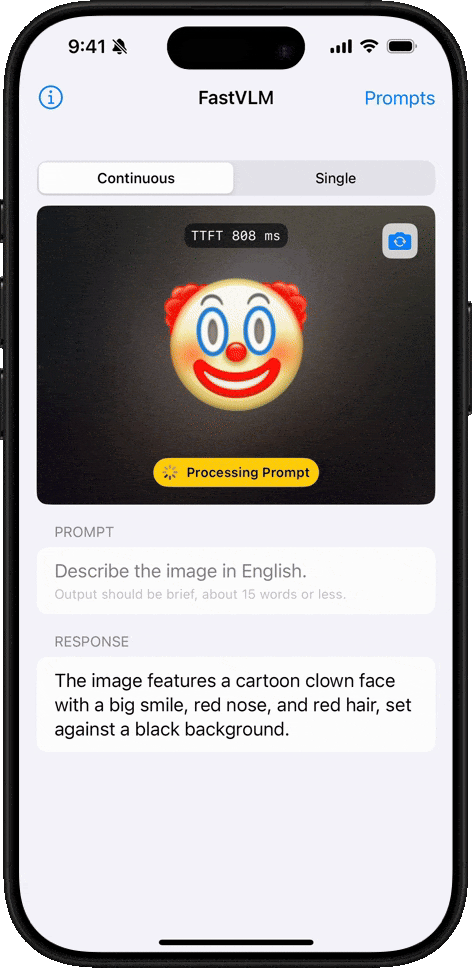
Comprensión de Emojis
Comparación de Rendimiento
Escenarios de Aplicación
Subtitulado de Imágenes
Genera automáticamente descripciones de texto vívidas y precisas para imágenes.
Respuesta Visual a Preguntas (VQA)
Comprende el contenido de la imagen y responde preguntas sobre la imagen.
Reconocimiento y Análisis de Imágenes
Reconoce objetos, texto o datos en imágenes para un análisis inteligente.
Especialmente adecuado para escenarios que requieren interacción en tiempo real de imagen y texto.
Descargas de Modelos
Checkpoints de PyTorch
| Modelo | Etapa | Enlace de Descarga |
|---|---|---|
| FastVLM-0.5B | 2 | fastvlm_0.5b_stage2 |
| FastVLM-0.5B | 3 | fastvlm_0.5b_stage3 |
| FastVLM-1.5B | 2 | fastvlm_1.5b_stage2 |
| FastVLM-1.5B | 3 | fastvlm_1.5b_stage3 |
| FastVLM-7B | 2 | fastvlm_7b_stage2 |
| FastVLM-7B | 3 | fastvlm_7b_stage3 |