它是如何工作的?
看懂图像
图像 → Token
Token → 语言
FastVLM 先高效地理解图像内容,将其转换为紧凑的标记 (Tokens),然后利用这些标记快速生成准确的文本描述或回答。
核心优势
极速响应
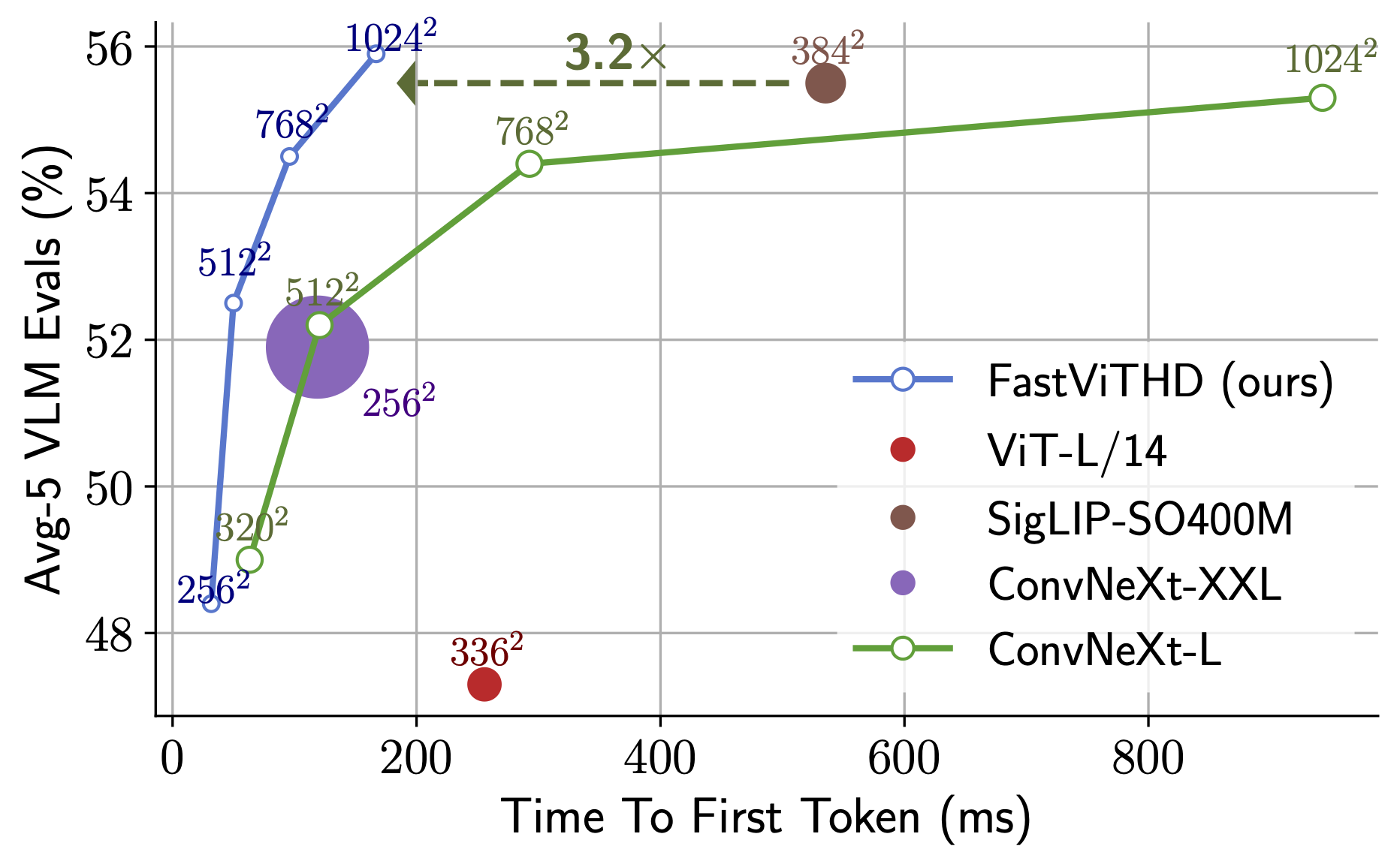
首 Token 输出速度惊人!FastVLM-0.5B 比 LLaVA-OneVision 快 85 倍。FastVLM-7B (结合 Qwen2) 比 Cambrian-1-8B 快 7.9 倍 (同等精度)。
小巧高效
模型体积小,部署更轻松。FastVLM-0.5B 比 LLaVA-OneVision 小 3.4 倍。非常适合 iPhone、iPad、Mac 等端侧设备。
端侧智能
无需依赖云端,直接在您的苹果设备上运行,保护隐私,响应更快。
完美适配 iOS/Mac 生态,赋能边缘 AI 应用。
示例展示
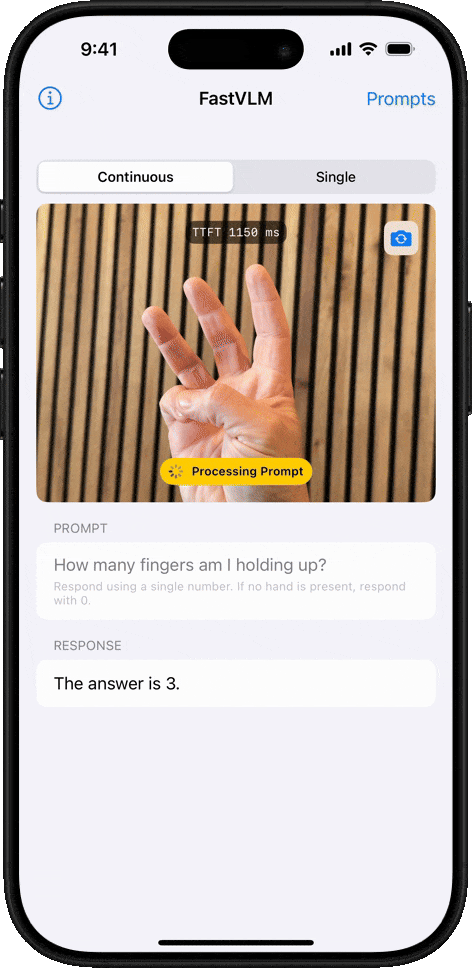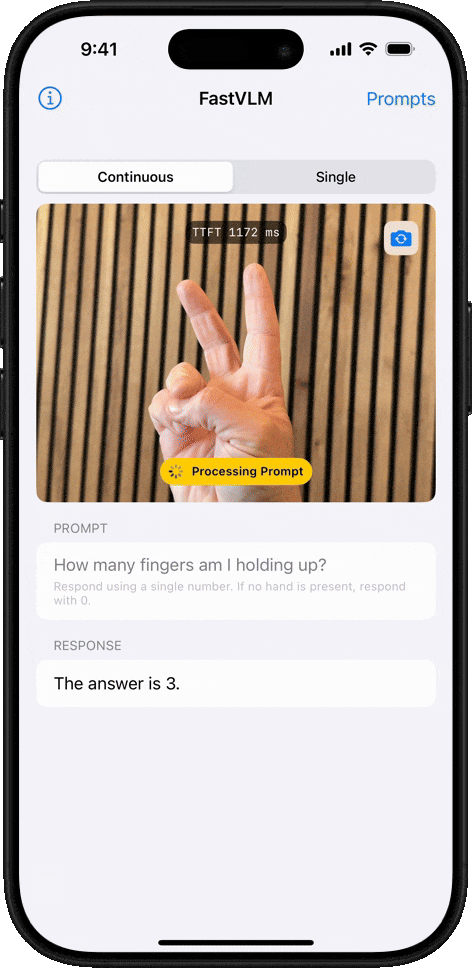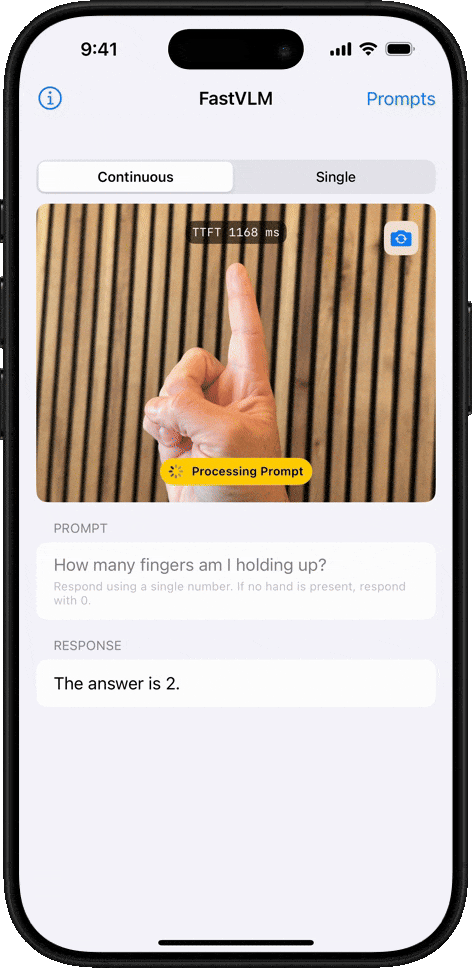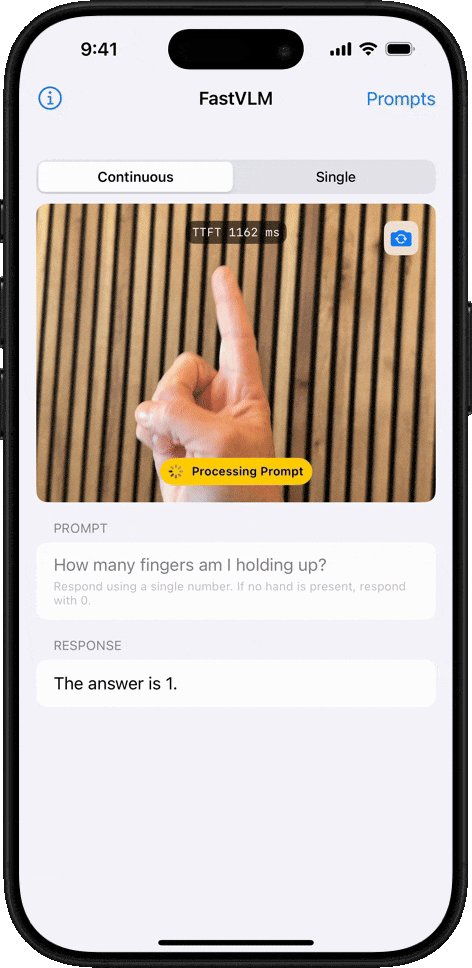
物体计数
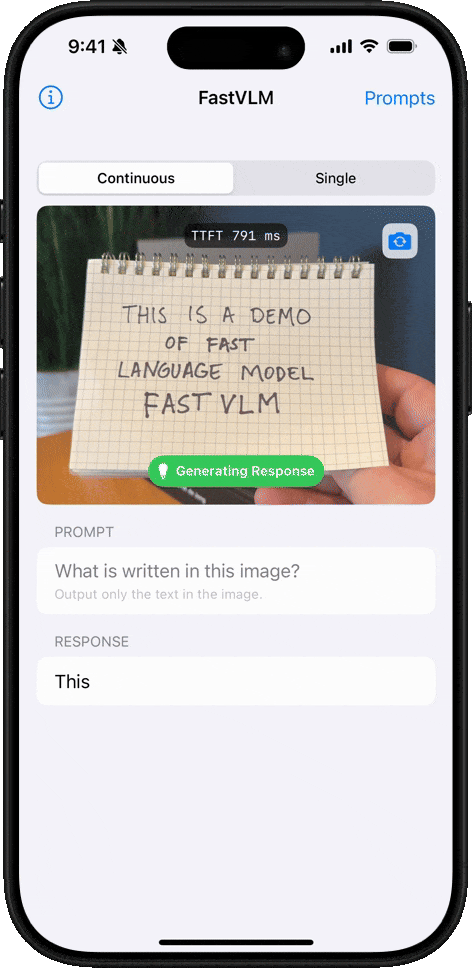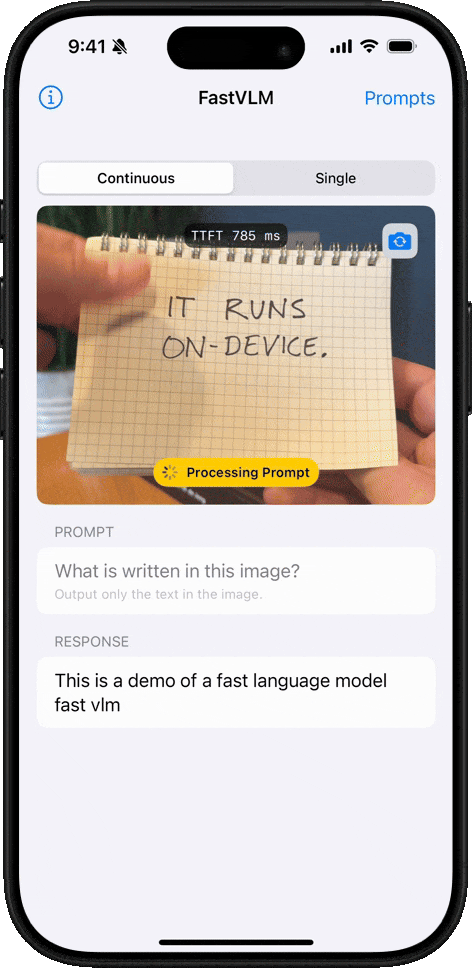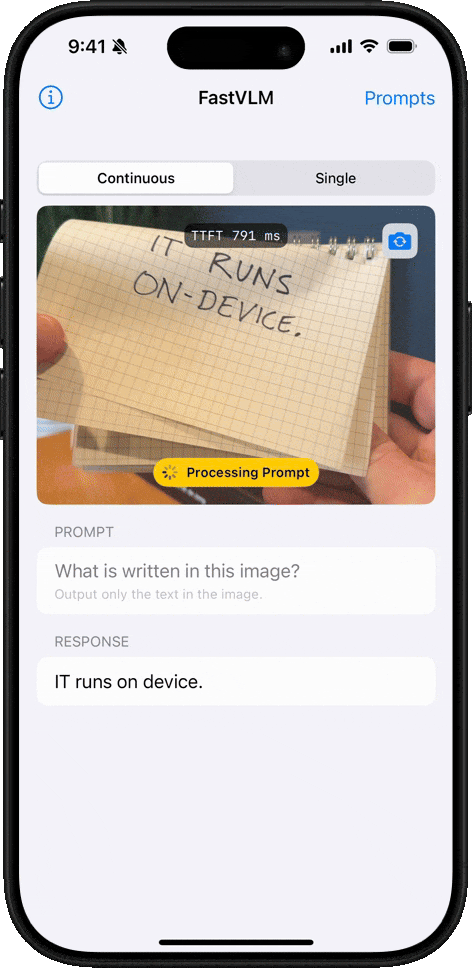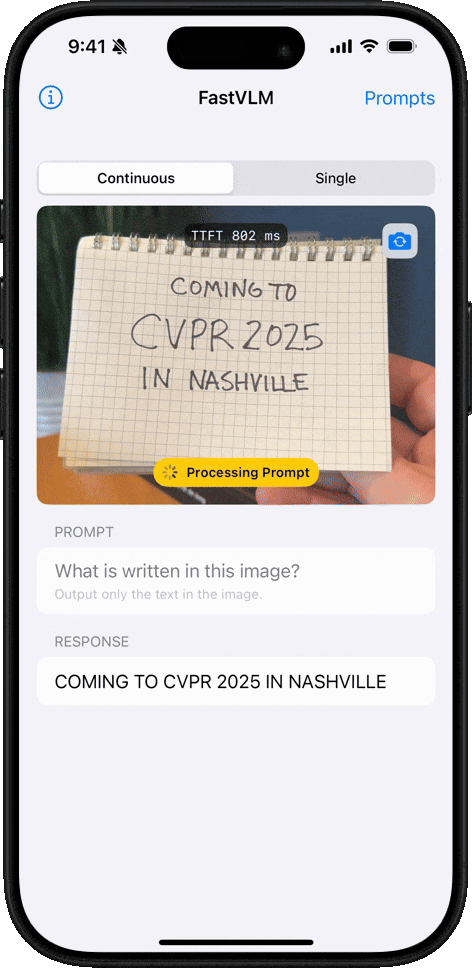
手写文字识别
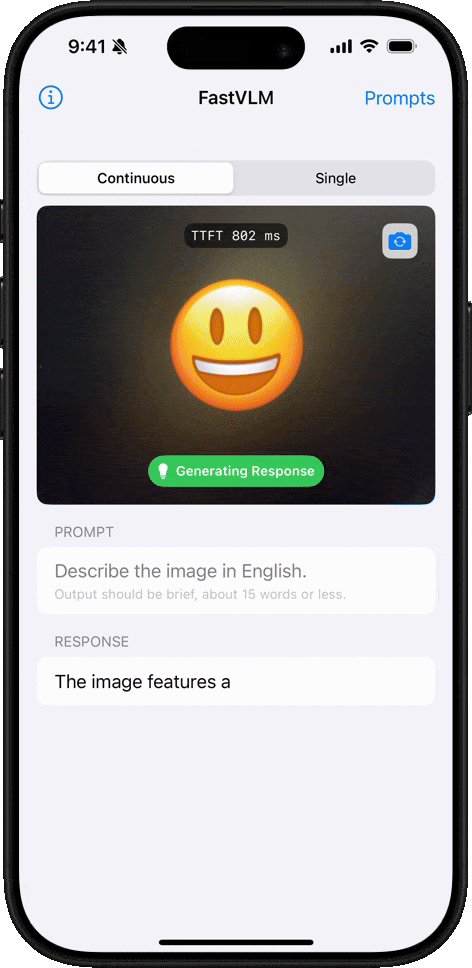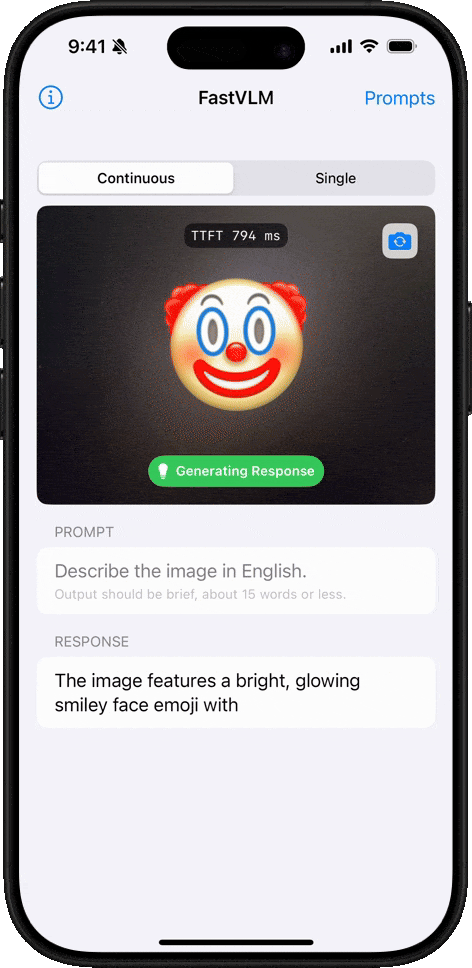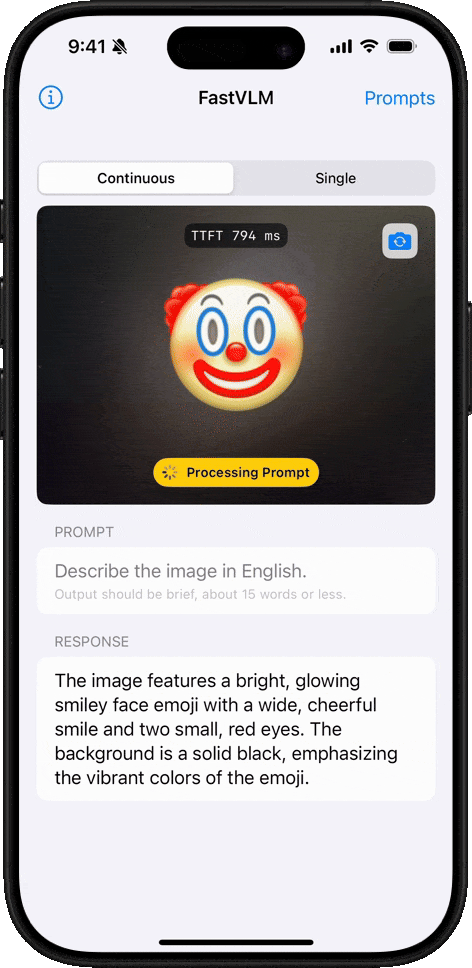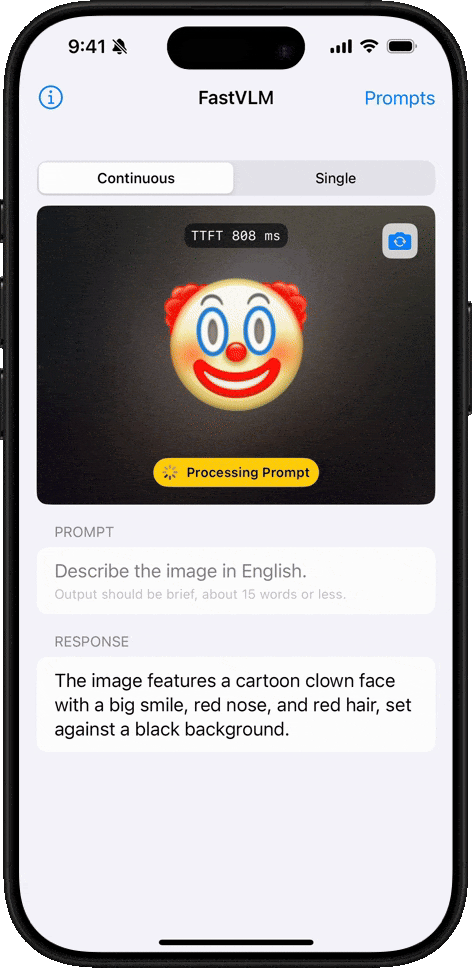
Emoji 理解
性能对比
应用场景
图像描述生成
自动为图片生成生动、准确的文字描述。
视觉问答 (VQA)
理解图片内容,并回答关于图片的提问。
图像识别与分析
识别图中的物体、文字或数据,进行智能分析。
特别适合需要实时处理图像和文本交互的场景。
模型下载
PyTorch Checkpoints
| 模型 (Model) | 阶段 (Stage) | 下载链接 (Download Link) |
|---|---|---|
| FastVLM-0.5B | 2 | fastvlm_0.5b_stage2 |
| FastVLM-0.5B | 3 | fastvlm_0.5b_stage3 |
| FastVLM-1.5B | 2 | fastvlm_1.5b_stage2 |
| FastVLM-1.5B | 3 | fastvlm_1.5b_stage3 |
| FastVLM-7B | 2 | fastvlm_7b_stage2 |
| FastVLM-7B | 3 | fastvlm_7b_stage3 |