어떻게 작동하나요?
이미지 이해
이미지 → 토큰
토큰 → 언어
FastVLM은 이미지 내용을 효율적으로 이해하고 컴팩트한 토큰으로 변환한 다음, 이 토큰을 사용하여 정확한 텍스트 설명이나 답변을 빠르게 생성합니다.
핵심 장점
초고속 응답
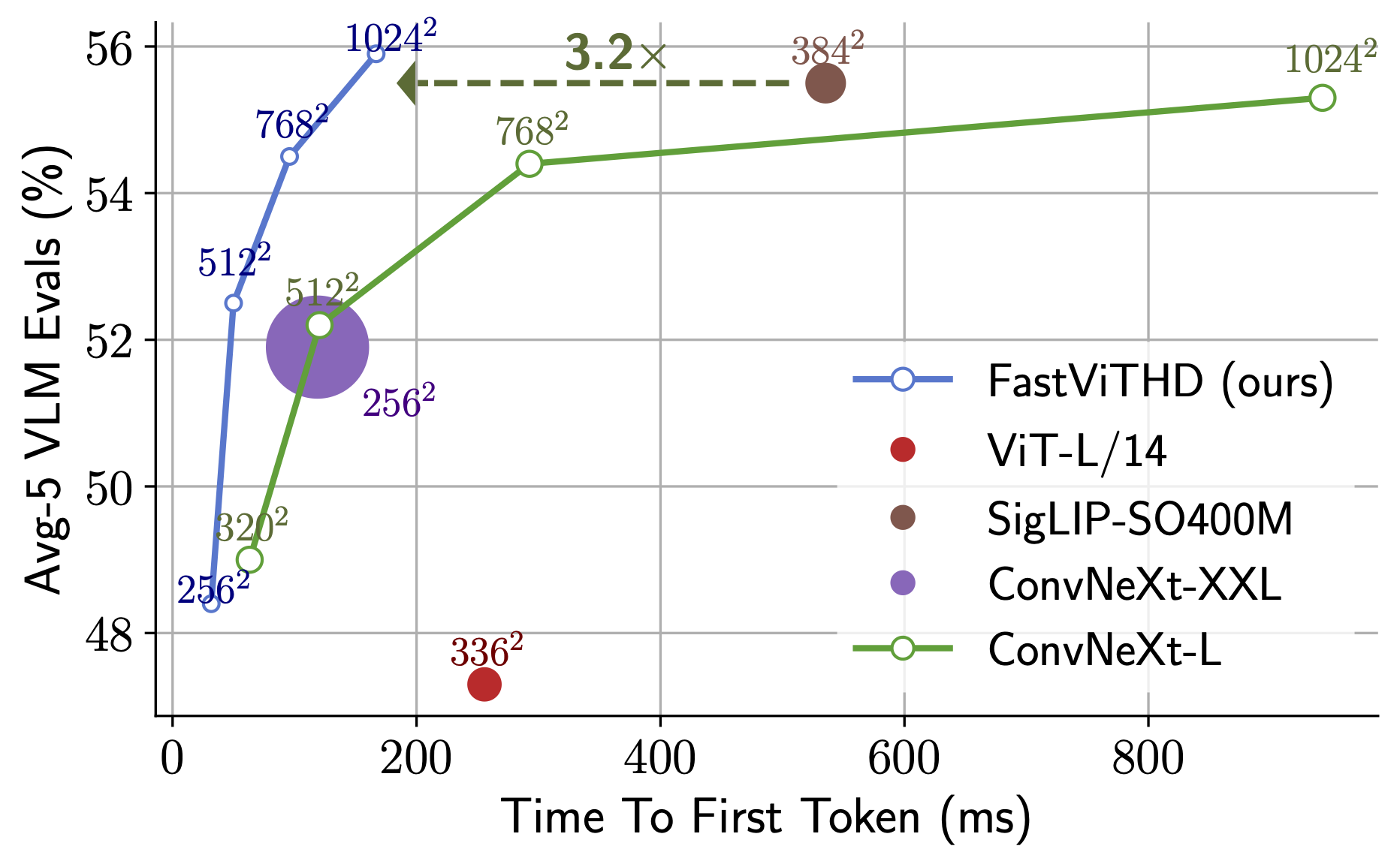
놀라운 첫 토큰 출력 속도! FastVLM-0.5B는 LLaVA-OneVision보다 85배 빠릅니다. FastVLM-7B(Qwen2 결합)는 Cambrian-1-8B보다 7.9배 빠릅니다(유사한 정확도에서).
컴팩트하고 효율적
작은 모델 크기, 더 쉬운 배포. FastVLM-0.5B는 LLaVA-OneVision보다 3.4배 작습니다. iPhone, iPad, Mac과 같은 기기 내 사용에 이상적입니다.
온디바이스 인텔리전스
클라우드 의존성 없음, Apple 기기에서 직접 실행하여 개인 정보 보호 및 더 빠른 응답.
iOS/Mac 생태계에 완벽하게 적용되어 엣지 AI 애플리케이션을 강화합니다.
예시 쇼케이스
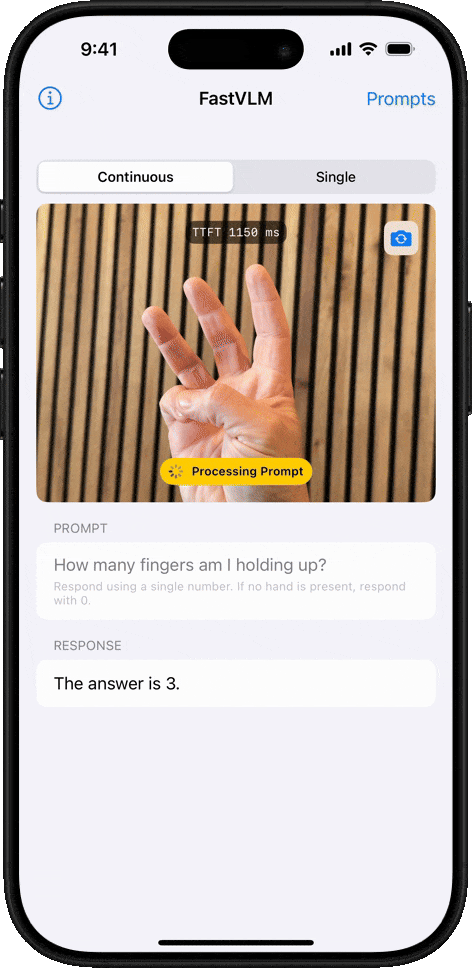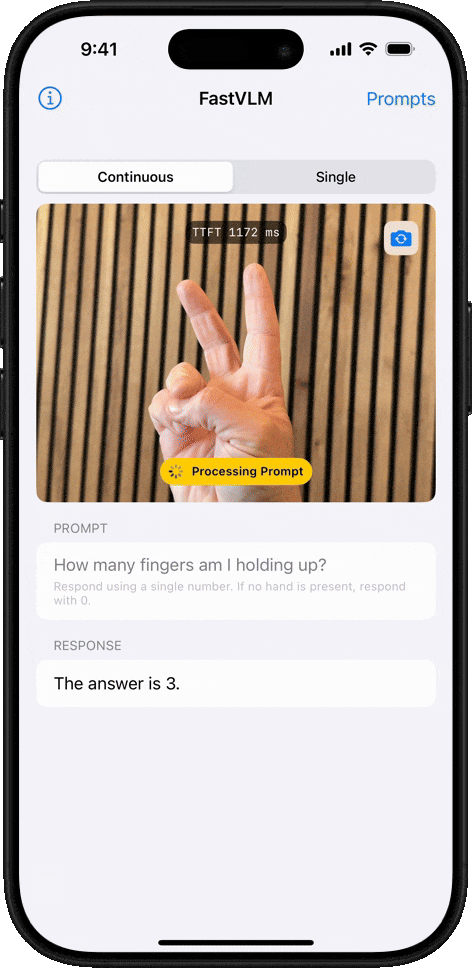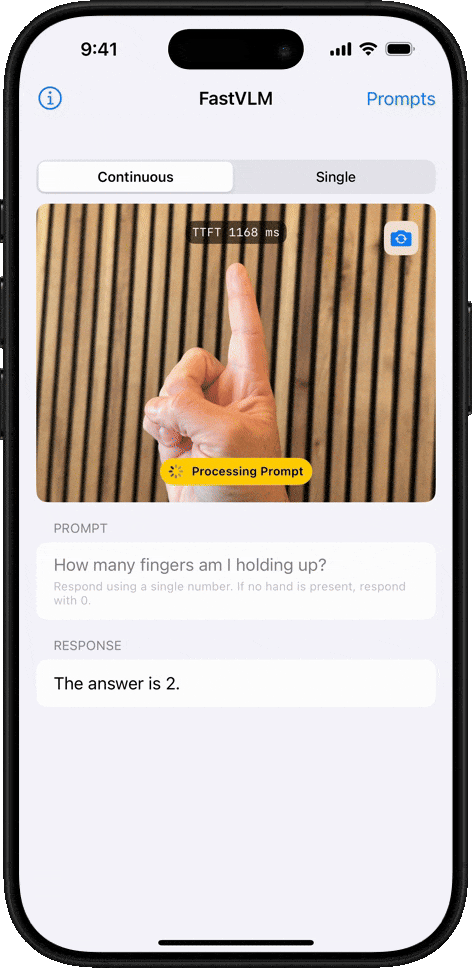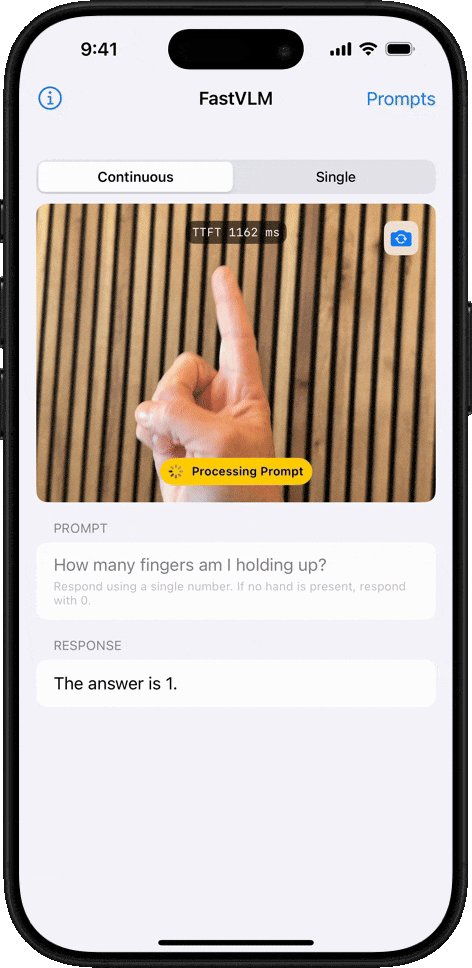
객체 개수 세기
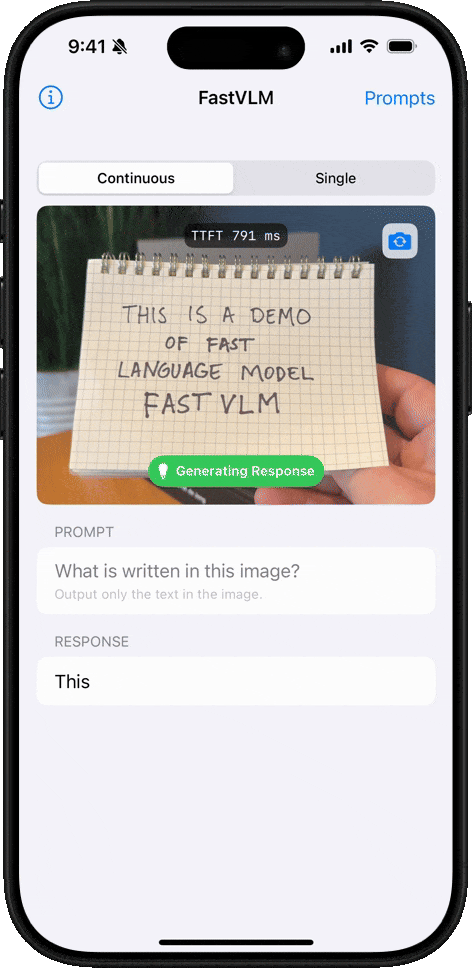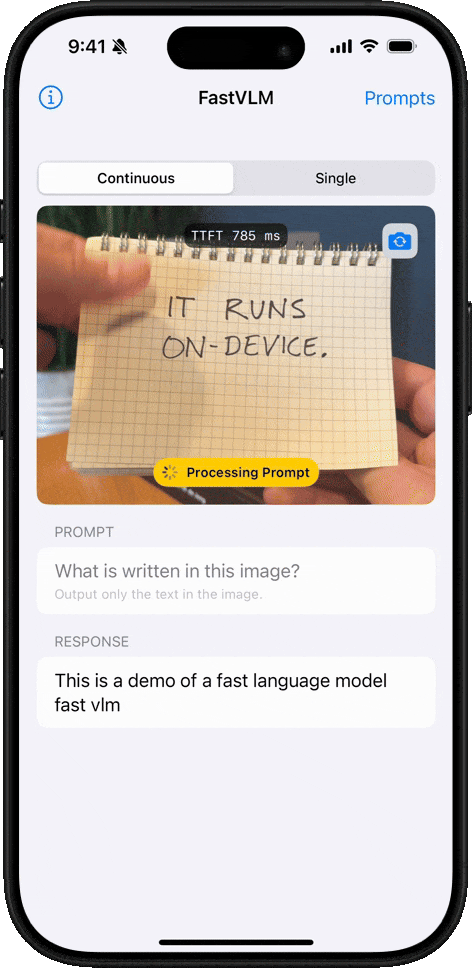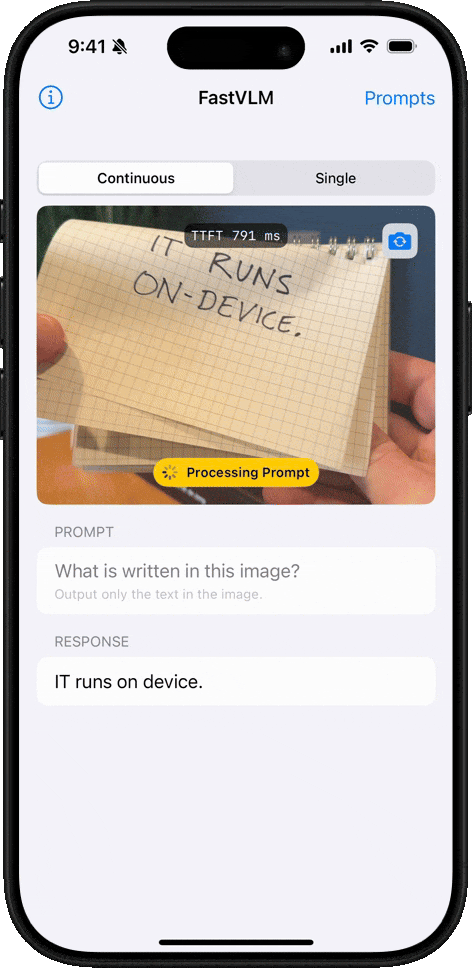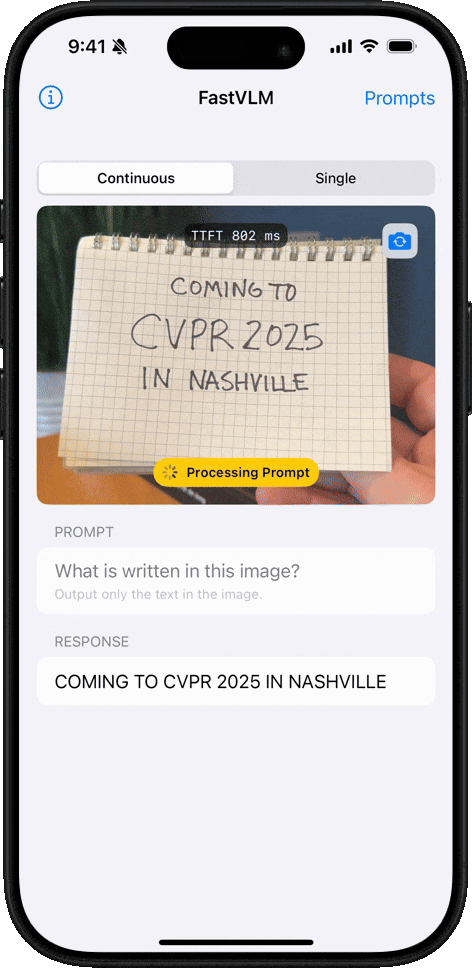
필기 인식
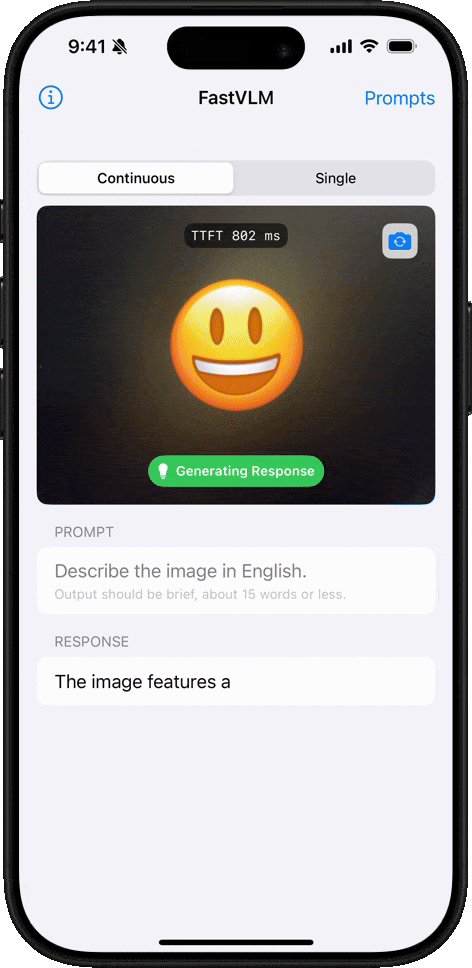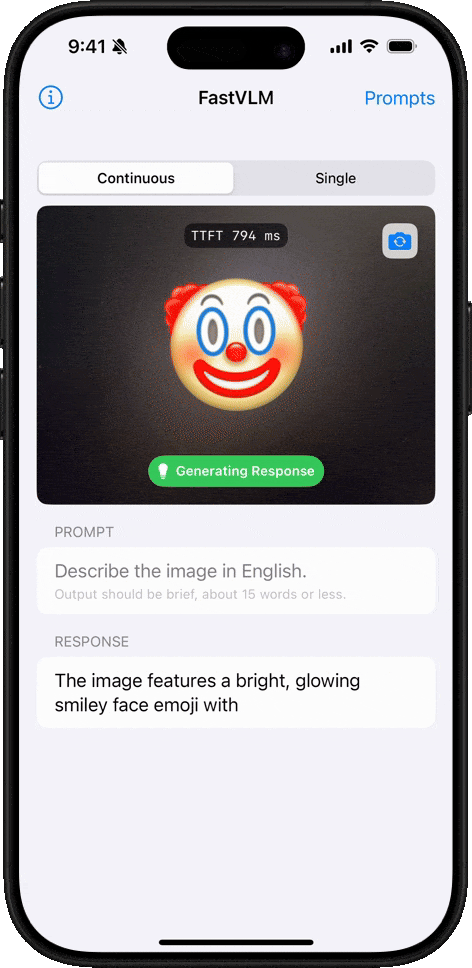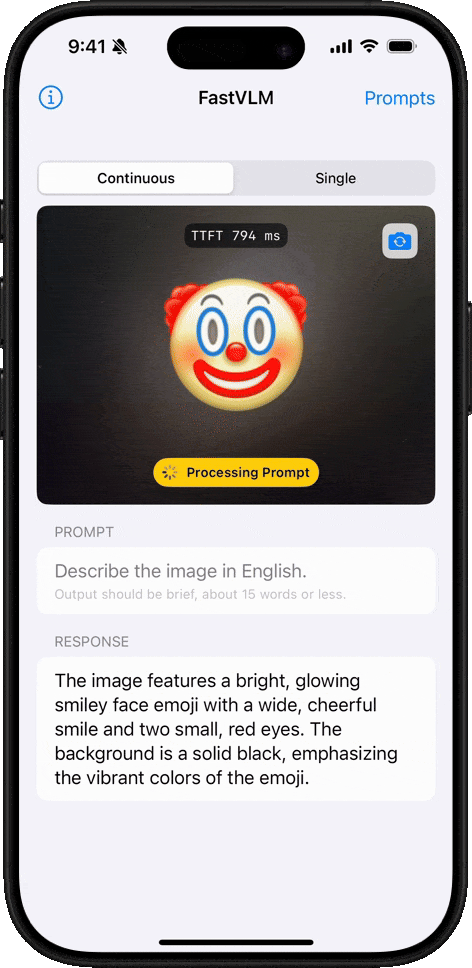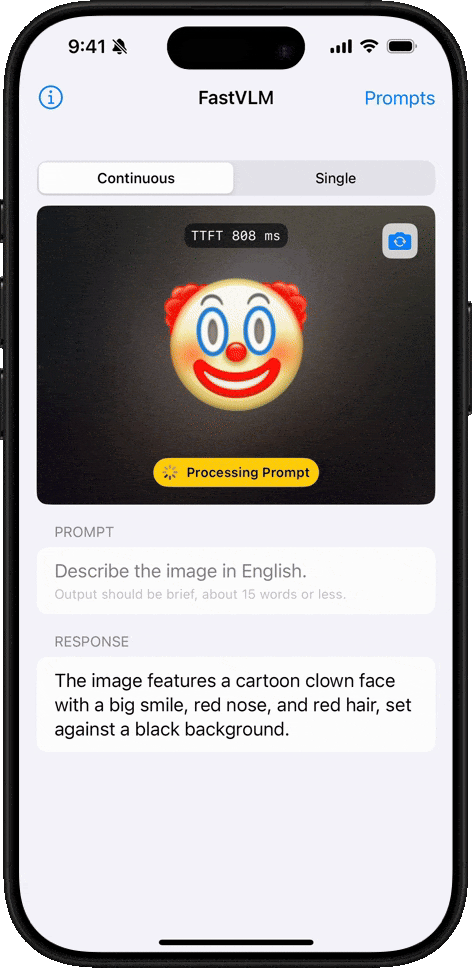
이모지 이해
성능 비교
적용 시나리오
이미지 캡셔닝
이미지에 대해 생생하고 정확한 텍스트 설명을 자동으로 생성합니다.
시각적 질의응답(VQA)
이미지 내용을 이해하고 이미지에 대한 질문에 답변합니다.
이미지 인식 및 분석
지능형 분석을 위해 이미지의 객체, 텍스트 또는 데이터를 인식합니다.
실시간 이미지 및 텍스트 상호 작용이 필요한 시나리오에 특히 적합합니다.
모델 다운로드
PyTorch 체크포인트
| 모델 | 단계 | 다운로드 링크 |
|---|---|---|
| FastVLM-0.5B | 2 | fastvlm_0.5b_stage2 |
| FastVLM-0.5B | 3 | fastvlm_0.5b_stage3 |
| FastVLM-1.5B | 2 | fastvlm_1.5b_stage2 |
| FastVLM-1.5B | 3 | fastvlm_1.5b_stage3 |
| FastVLM-7B | 2 | fastvlm_7b_stage2 |
| FastVLM-7B | 3 | fastvlm_7b_stage3 |