How does it work?
FastVLM efficiently understands image content, converts it into compact tokens, and then uses these tokens to quickly generate accurate text descriptions or answers.
Core Advantages
Extreme Speed
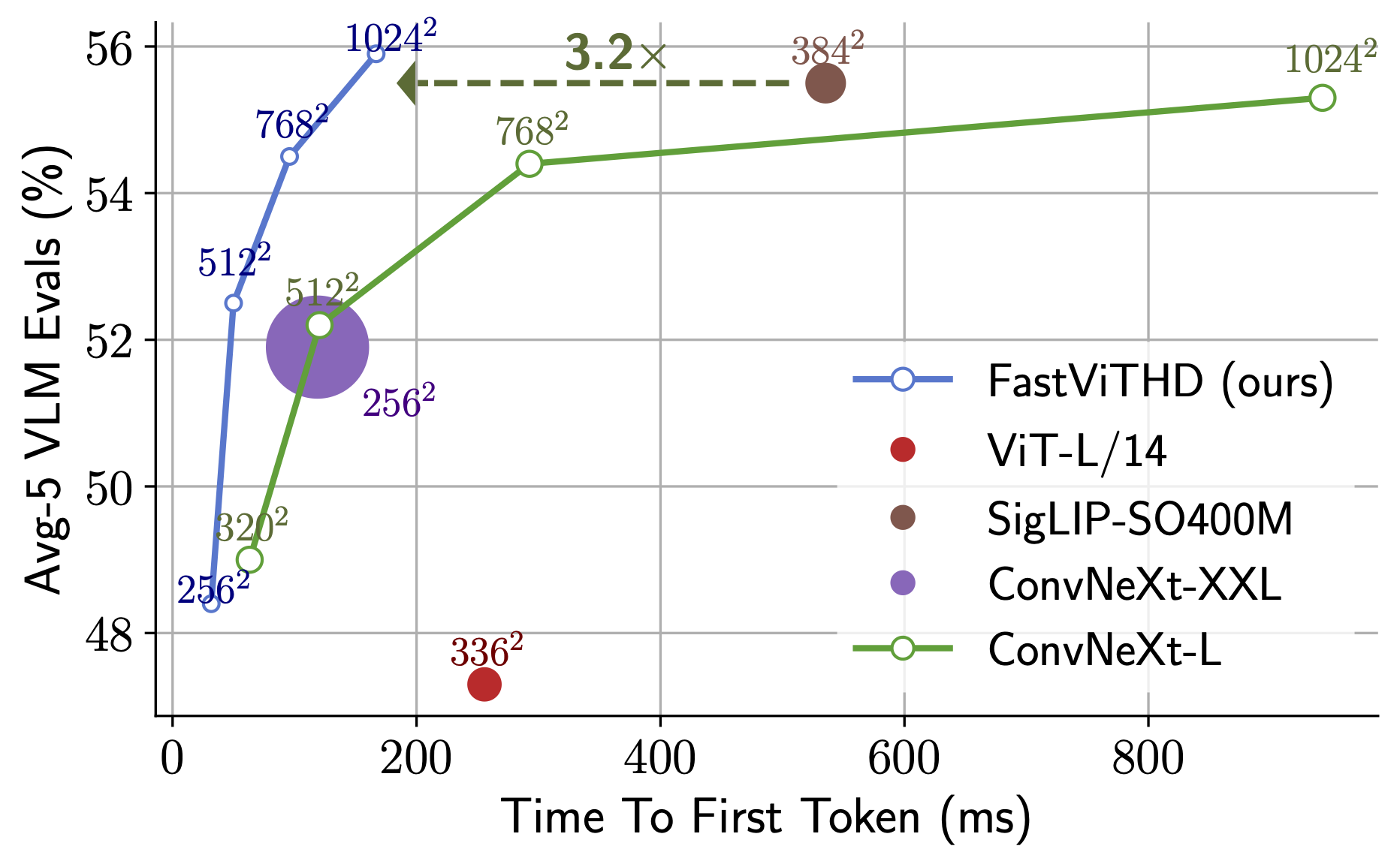
Astonishing first token output speed! FastVLM-0.5B is 85x faster than LLaVA-OneVision. FastVLM-7B (with Qwen2) is 7.9x faster than Cambrian-1-8B (at similar accuracy).
Compact & Efficient
Small model size, easier deployment. FastVLM-0.5B is 3.4x smaller than LLaVA-OneVision. Ideal for on-device use like iPhone, iPad, Mac.
On-Device Intelligence
No cloud dependency, runs directly on your Apple device, protecting privacy and responding faster.
Perfectly adapted to the iOS/Mac ecosystem, empowering edge AI applications.
Examples Showcase
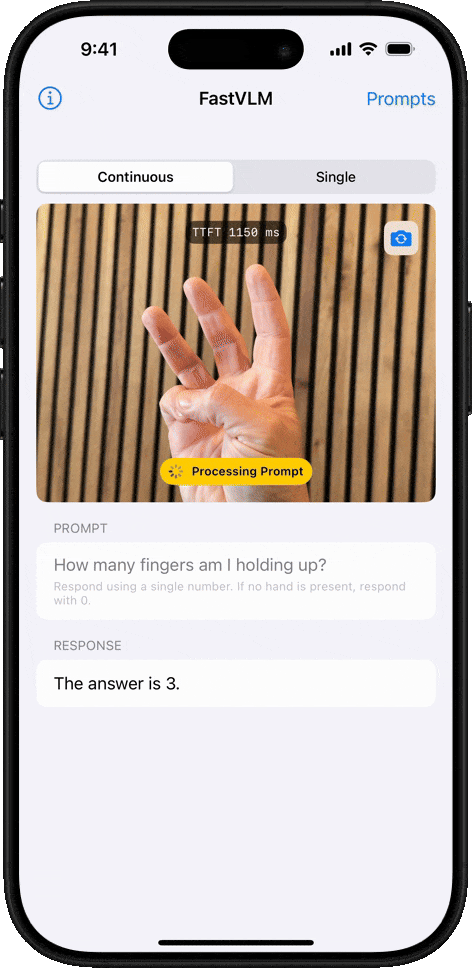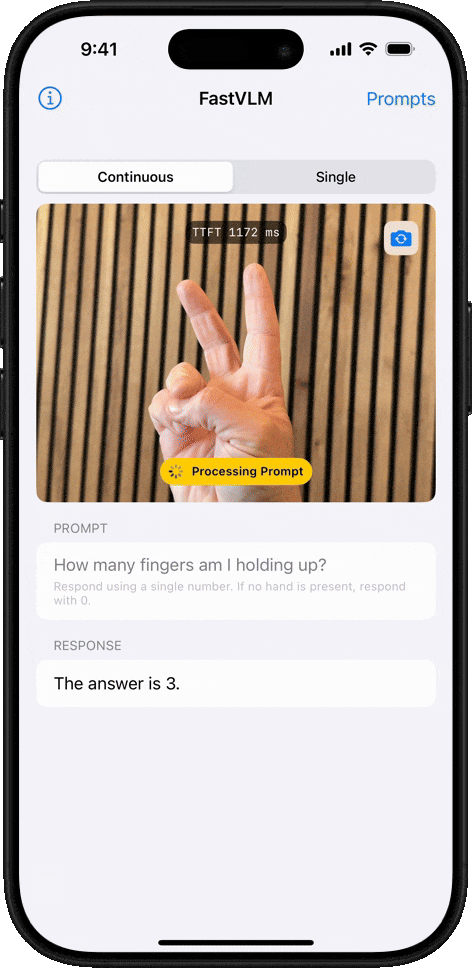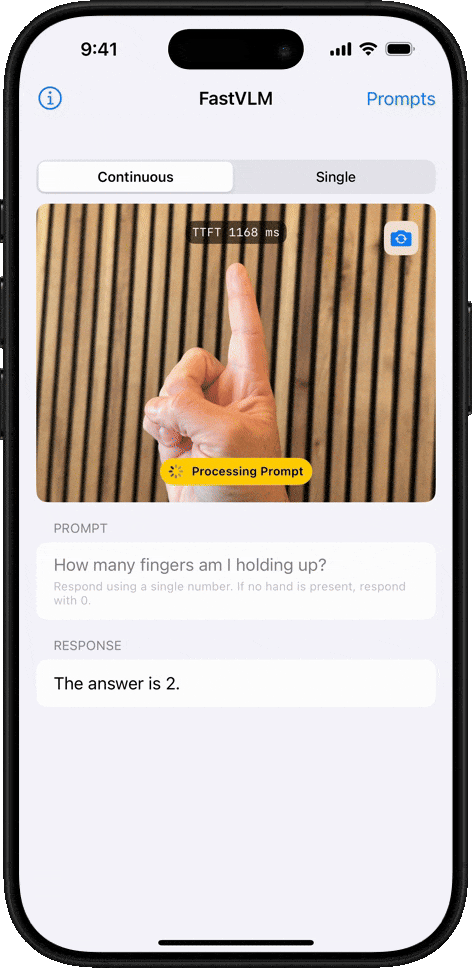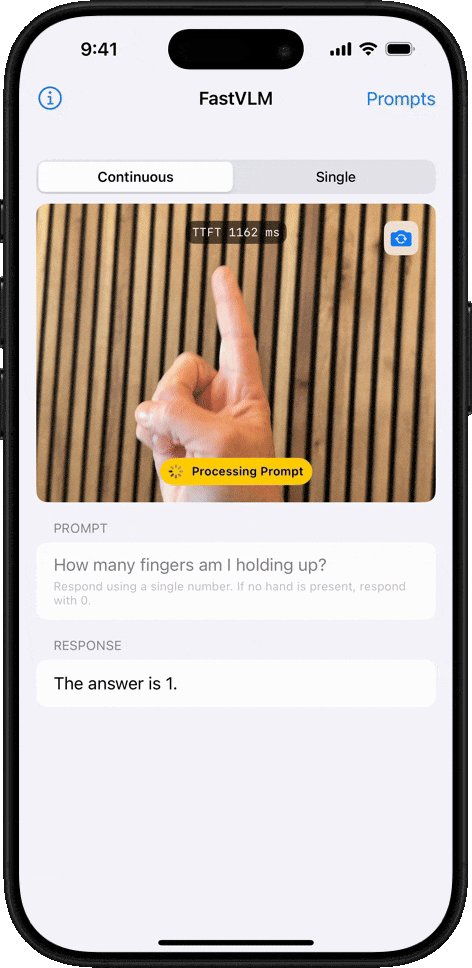
Object Counting
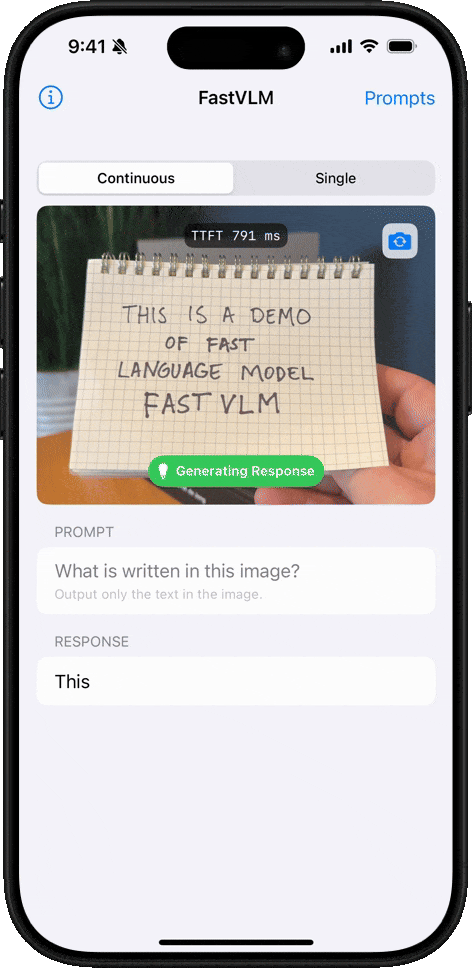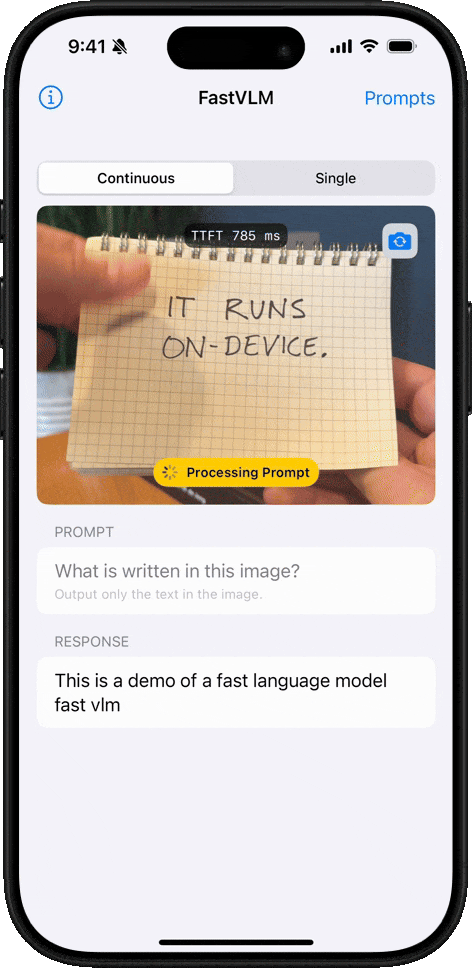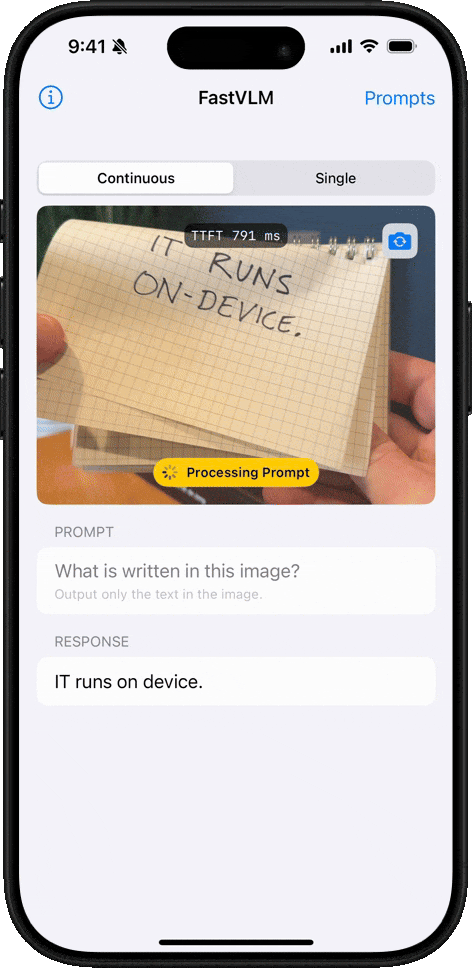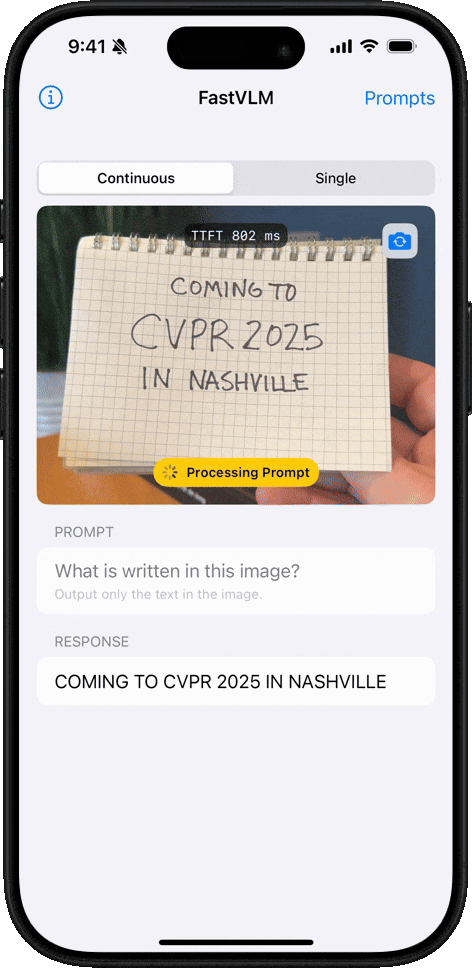
Handwriting Recognition
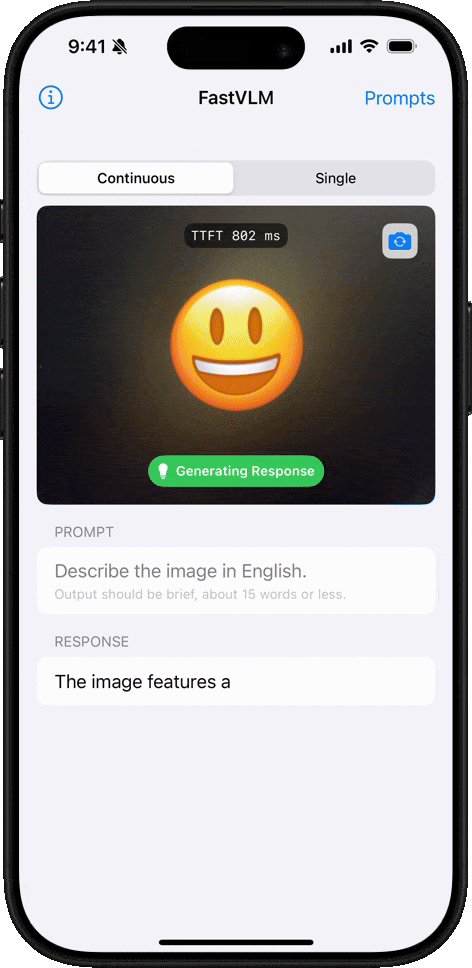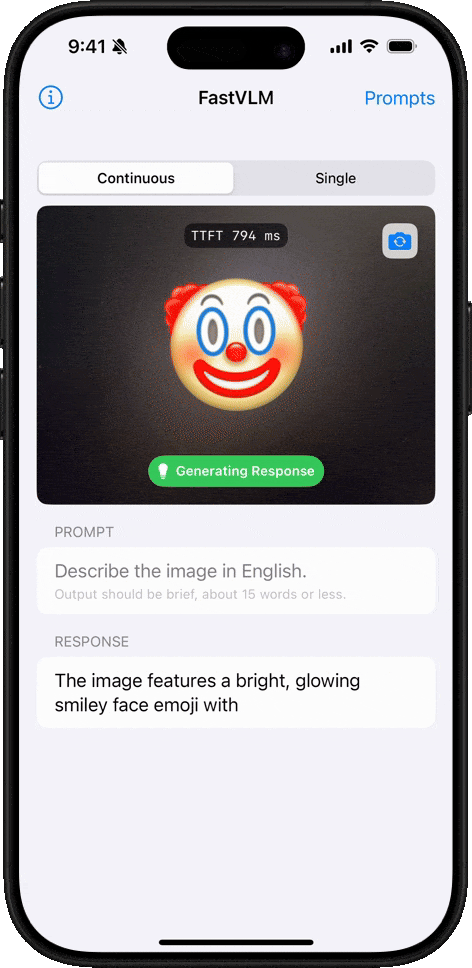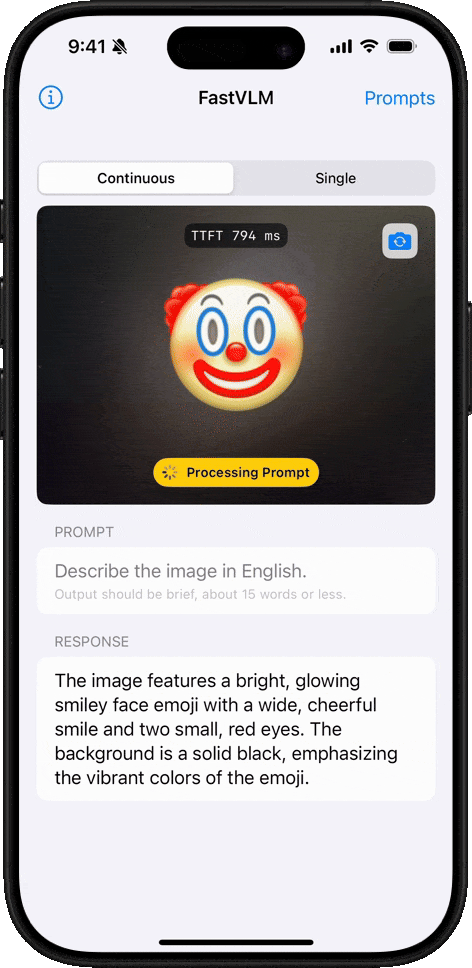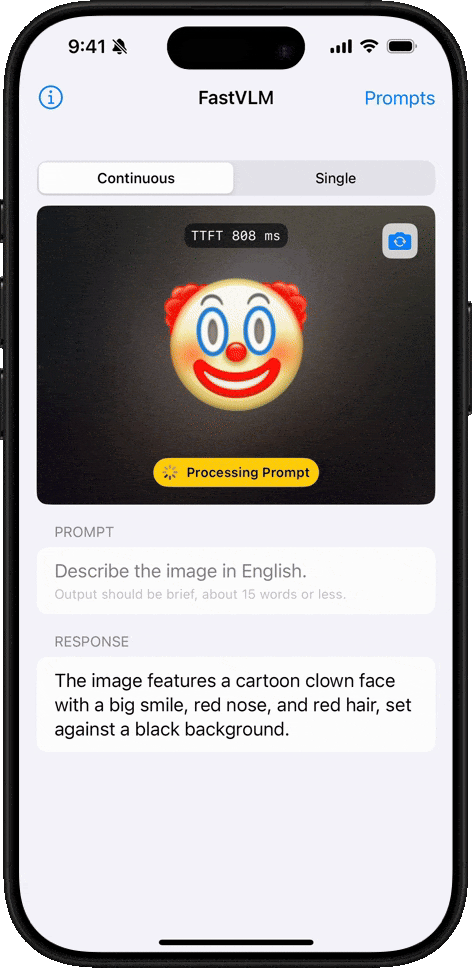
Emoji Understanding
Performance Comparison
Application Scenarios
Image Captioning
Automatically generate vivid and accurate text descriptions for images.
Visual Question Answering (VQA)
Understand image content and answer questions about the image.
Image Recognition & Analysis
Recognize objects, text, or data in images for intelligent analysis.
Especially suitable for scenarios requiring real-time image and text interaction.
Model Downloads
PyTorch Checkpoints
| Model | Stage | Download Link |
|---|---|---|
| FastVLM-0.5B | 2 | fastvlm_0.5b_stage2 |
| FastVLM-0.5B | 3 | fastvlm_0.5b_stage3 |
| FastVLM-1.5B | 2 | fastvlm_1.5b_stage2 |
| FastVLM-1.5B | 3 | fastvlm_1.5b_stage3 |
| FastVLM-7B | 2 | fastvlm_7b_stage2 |
| FastVLM-7B | 3 | fastvlm_7b_stage3 |